Search results for Kimi
Kimi community
One keyword maps to one global community path.
People
Not Found
Tweets including Kimi

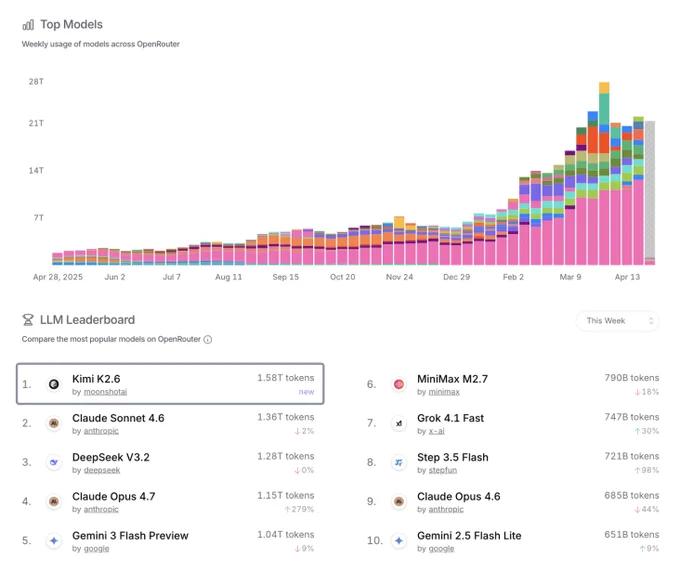
Kimi K2.6 is now #1# on OpenRouter's weekly LLM Leaderboard 🏆
A huge thank you to every developer building with Kimi. We'll keep our heads down and keep shipping.

Kimi K2.6 is the new SOTA open model in Vision and Document Arena, with solid gains since Kimi K2.5:
- #1# open on Vision Arena (#15# overall), +14 over #2# Kimi K2.5 (Thinking)
- #1# open on Document Arena (#8# overall), +9 over K2.5 and on par with proprietary models like Muse Spark and Gemini 3.1 Pro.
Huge congrats again to the @Kimi_Moonshot team on the open source progress!
Show more


Kimi K2.6 becomes the #1# open model on MathArena!


Kimi K2.6 is free on Nous Portal for the next 24 hours
Made possible by @vercel's AI Gateway & @Kimi_Moonshot
Run 'hermes update', then 'hermes model' and select Kimi K2.6 to try out one of the most impressive open model releases ever
Show more

Kimi K2.6 is now ranked #1# on OpenRouter's programming leaderboard.


Kimi K2.6 is now live inside Anything!

Kimi K2.6 autonomously overhauled exchange-core, an 8-year-old open-source financial matching engine.
Over a 13-hour execution, the model iterated through 12 optimization strategies, initiating over 1,000 tool calls to precisely modify more than 4,000 lines of code. Acting as an expert systems architect, Kimi K2.6 analyzed CPU and allocation flame graphs to pinpoint hidden bottlenecks and boldly reconfigured the core thread topology (from 4ME+2RE to 2ME+1RE).
Despite the engine already operating near its performance limits, Kimi K2.6 extracted a 185% medium throughput leap (from 0.43 to 1.24 MT/s) and a 133% performance throughput gain (soaring from 1.23 to 2.86 MT/s).
Show more

Kimi K2.6 demonstrates strong long-horizon coding in complex engineering tasks:
Kimi K2.6 successfully downloaded and deployed the Qwen3.5-0.8B model locally on a Mac. By implementing and optimizing model inference in Zig—a highly niche programming language—it demonstrated exceptional out-of-distribution generalization.
Across 4,000+ tool calls, over 12 hours of continuous execution, and 14 iterations, Kimi K2.6 dramatically improved throughput from ~15 to ~193 tokens/sec, ultimately achieving speeds ~20% faster than LM Studio.
Show more


Kimi K2.6 @Kimi_Moonshot is the new leading open-weights agent model, landing at #4# on Claw-Eval (Pass^3: 62.3%).
Key takeaways:
- 👑 Best open-source agent, period: Pass^3 of 62.3% is the highest of any open-weights model, within 8 points of frontier Claude Opus 4.6 (70.4%). Pass@3 of 80.9% closes most of the gap to closed models.
- 💪Frontier-tier robustness: 94.7 (±0.9) — statistically tied with Claude Sonnet 4.6 (94.6) and Claude Opus 4.6 (94.2). K2.6's agent trajectories no longer collapse under perturbation.
The open-source agent frontier just moved.
Full Leaderboard:
Show more

Kimi is the current open-source SOTA on Artificial Analysis

Moonshot’s Kimi K2.6 is the new leading open weights model. Kimi K2.6 lands at #4# on the Artificial Analysis Intelligence Index (54) behind only Anthropic, Google, and OpenAI (all 57)
Key takeaways:
➤ Increase in performance on agentic tasks: @Kimi_Moonshot's Kimi K2.6 achieves an Elo of 1520 on our GDPval-AA evaluation, which is a marked improvement over Kimi K2.5’s Elo of 1309. GDPval-AA is our leading metric for general agentic performance, measuring the performance on knowledge work tasks such as preparing presentations and analysis. Models are given code execution and web browsing tools in an agentic loop via our open source reference agentic harness called Stirrup. This continues Kimi K2.6’s strength in tool use, maintaining a 96% score on τ²-Bench Telecom, placing it among other frontier models in this category.
➤ Low hallucination rate: Kimi K2.5 scores 6 on the AA-Omniscience Index, our knowledge evaluation measuring both accuracy and hallucination rate. This score is primarily driven by a comparatively low hallucination rate of 39% (reduced from Kimi K2.5’s 65%), indicating a greater capability to abstain rather than fabricate knowledge when the model is uncertain. Kimi K2.6’s low hallucination rate places it similarly to other models such as Claude Opus 4.7 (36%) and MiniMax-M2.7 (34%)
➤ High token usage: Kimi K2.6 demonstrates high token usage, but is in line with other frontier models in the same intelligence tier. To run the full Artificial Analysis Intelligence Index, Kimi K2.6 used ~160M reasoning tokens. This is slightly lower than Claude Sonnet 4.6 (~190M reasoning tokens) but much higher than GPT 5.4 (~110M reasoning tokens).
➤ Open weights: Kimi K2.6 is a Mixture-of-Experts (MoE) model with 1T total parameters and 32B active, same as the previous two generations of models Kimi K2 Thinking and Kimi K2.5. Kimi K2.6 again pushes the open weights frontier in intelligence.
➤ Third Party Access: Kimi K2.6 is accessible through Moonshot’s First Party API as well as third party API providers Novita, Baseten, Fireworks, and Parasail
➤ Multimodality: Kimi K2.6 supports Image and Video input and text output natively. The model’s max context length remains 256k.
Further analysis in the threads below.
Show more
