Search results for Benchmark
Benchmark community
One keyword maps to one global community path.
People
Not Found
Tweets including Benchmark

Benchmark says SEC's NMS proposal is the 'most consequential' US crypto rule this year


The benchmark is shifting, from “how human-like the output is” to “whether contribution is provable and payouts are programmable.”
That’s not rhetoric; it’s a shift in monetization boundaries.
Show more


India's share benchmarks slip as Mideast peace deal hopes ebb


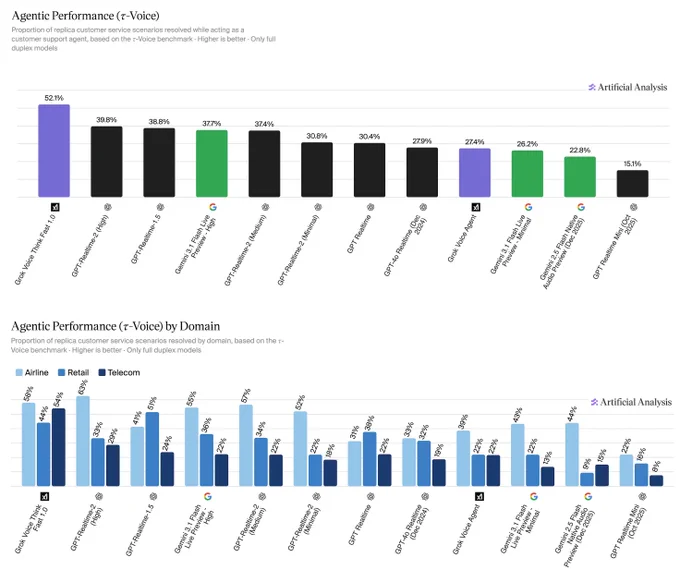
Announcing agentic performance benchmarking for Speech to Speech models on Artificial Analysis. We use 𝜏-Voice to measure tool calling and customer interaction voice agent capabilities in realistic customer service scenarios
Even the strongest Speech to Speech (S2S) models today resolve only about half of realistic customer service scenarios end-to-end - a meaningful gap relative to frontier text-based agents on the same tasks. Voice channels introduce significant complexity: challenging accents, background noise, and packet loss, all while requiring fast responses, consistency across long multi-turn conversations, and reliable tool use. Performance also varies considerably by audio condition: in clean audio some models perform notably better, but realistic conditions continue to pose a challenge. Conversation duration also varies meaningfully across models, with implications for both customer experience and operational cost.
About 𝜏-Voice:
Our Agentic Performance benchmark is based on 𝜏-Voice (Ray, Dhandhania, Barres & Narasimhan, 2026), which extends 𝜏²-bench into the voice modality to evaluate S2S models on realistic customer service tasks. It measures multi-turn instruction following, support of a simulated customer through a complete interaction, and tool use against simulated customer service systems. The simulated user combines an LLM-driven decision model with realistic audio synthesis: diverse accents, background noise, and packet loss modelled on real network conditions.
This complements our Big Bench Audio benchmark measuring intelligence and Conversational Dynamics (Full Duplex Bench subset) benchmark measuring conversational naturalness. Scores are the average of three independent pass@1 trials. We evaluate under realistic audio conditions using the 𝜏²-bench base task split across three domains:
➤ Airline (50 scenarios): e.g., changing a flight, rebooking under policy constraints
➤ Retail (114 scenarios): e.g., disputing a charge, processing a return
➤ Telecom (114 scenarios): e.g., resolving a billing issue, troubleshooting a service problem
Task success is determined by deterministic checks against expected actions and final database state, consistent with the 𝜏²-bench evaluator.
Key results:
xAI's Grok Voice Think Fast 1.0 is the clear leader at 52.1%, averaging 5.6 minutes per conversation, the second-longest overall. OpenAI's GPT-Realtime-2 (High) (39.8%, 3.0 min) and GPT-Realtime-1.5 (38.8%, 4.8 min) follow, with Gemini 3.1 Flash Live Preview - High close behind at 37.7% (3.8 min).
Speech to Speech is a fast evolving modality and we expect movement in rankings as we continue to add new models with these capabilities, and model robustness improves.
Congratulations @xAI @elonmusk! See below for further detail ⬇️
Show more

IS PI THE BENCHMARK FOR CRYPTO OGS?
Veteran market participants face scrutiny as Justin Wu (@Hackaprenuer) asserts that holding $PI is the definitive measure of success for long-term crypto investors.
The claim suggests that any participant who has been active for over five years and lacks exposure to Pi Network (@PiCoreTeam) has fundamentally failed to navigate the evolving retail landscape.
Is "OG" status now tied to capturing widespread mobile-mining adoption rather than early-stage $BTC or $ETH accumulation?
What is your take?
Show more


Update on the Benchmarks for USDe and mHYPER Markets.
The benchmarks for @ethena srUSDe and @MidasRWA x @hyperithm srmHYPER will now return to the current supply-weighted average of USDC and USDT lending rates on Aave V3 Core.
Strata is reverting the benchmarks with immediate effect to reflect recovering stablecoin markets on @aave v3 core.
Show more