Total amt of flops across all the GPUs in the world has grown about 3x per year for the last few years. Total amt of inference demand has probably grown ~10x per year. What happens when those lines cross?
The econ answer is: when demand > supply, price goes up. That might be true (even H100s are more expensive than they have ever been...) but doesn't actually solve the problem on its own here - demand continues to grow as we unlock new use cases and there is only so much additional supply coming.
To get to a healthy equilibrium, we also need to shift much more usage to smaller, targeted models. This will happen naturally as the incentives make sense for it: it's much easier to 10x your agent usage if you know that you can now solve 90% of your tasks with good cheap, fast models.
SWE 1.6 is not a general model. But we have trained it to specifically be good at the kinds of standard coding tasks that our users run. And thanks to its small size & a little magic from Cerebras it can run very cheaply at ~1000 tokens / sec. Give it a try and let us know what you think!
Show more

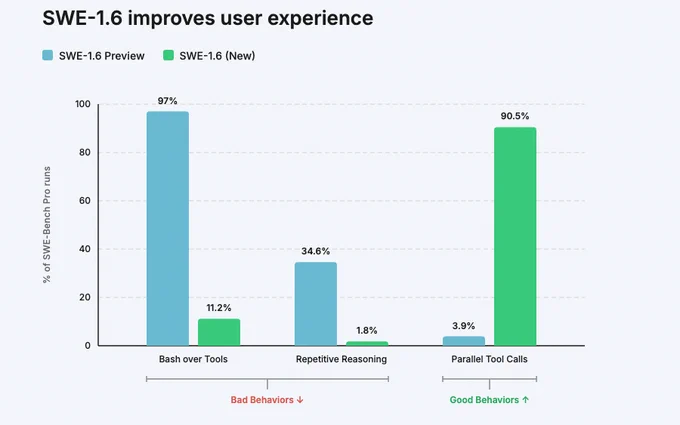
We’re releasing SWE-1.6, our best model in both intelligence & model UX. SWE-1.6 matches our Preview model on SWE-Bench Pro while dramatically improving on various behavioral axes.
It’s available today in Windsurf in two modes: free tier (200 tok/s) and fast tier (950 tok/s).
Show more