Search results for 0831ぶいすぽスノハレ併せ
0831ぶいすぽスノハレ併せ community
One keyword maps to one global community path.
People
Not Found
Tweets including 0831ぶいすぽスノハレ併せ

🧟♀️ @cos_hachiren3
🍂 @shima_e_bunnys
🦚 @YURIKOTIGER
#見た人も何か無言で3人組をあげる#
#0831ホロID全員集合# #hololiveID#
#Reinessance# #graveyART# #anyatelier#
Show more


Foreign born population of each country :
Jan 2001 Jan 2025
🇦🇹 8.7% 22.5%
🇧🇪 8.4% 20.2%
🇩🇰 4.8% 14.4%
🇫🇷 5.5% 14.0%
🇩🇪 8.9% 20.5%
🇬🇷 6.9% 11.0%
🇮🇸 3.1% 21.8%
🇮🇪 4.0% 23.3%
🇱🇺 37.5% 51.5%
🇳🇱 4.1% 16.8%
🇳🇴 4.1% 18.7%
🇸🇮 2.1% 15.5%
🇪🇸 3.4% 19.3%
🇸🇪 5.3% 20.8%
🇬🇧 4.3% 20.0%
Now add children born to foreign parents and the situation looks even worse.
We are living through the demographic annihilation of the people of Europe.
Show more

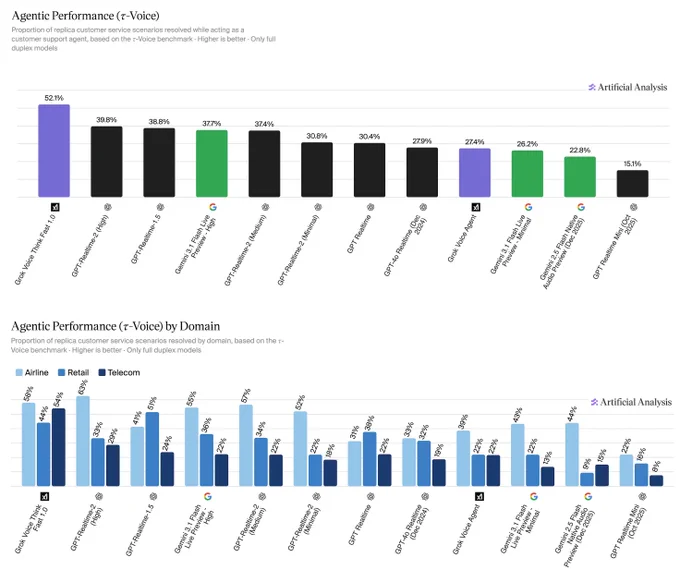
Announcing agentic performance benchmarking for Speech to Speech models on Artificial Analysis. We use 𝜏-Voice to measure tool calling and customer interaction voice agent capabilities in realistic customer service scenarios
Even the strongest Speech to Speech (S2S) models today resolve only about half of realistic customer service scenarios end-to-end - a meaningful gap relative to frontier text-based agents on the same tasks. Voice channels introduce significant complexity: challenging accents, background noise, and packet loss, all while requiring fast responses, consistency across long multi-turn conversations, and reliable tool use. Performance also varies considerably by audio condition: in clean audio some models perform notably better, but realistic conditions continue to pose a challenge. Conversation duration also varies meaningfully across models, with implications for both customer experience and operational cost.
About 𝜏-Voice:
Our Agentic Performance benchmark is based on 𝜏-Voice (Ray, Dhandhania, Barres & Narasimhan, 2026), which extends 𝜏²-bench into the voice modality to evaluate S2S models on realistic customer service tasks. It measures multi-turn instruction following, support of a simulated customer through a complete interaction, and tool use against simulated customer service systems. The simulated user combines an LLM-driven decision model with realistic audio synthesis: diverse accents, background noise, and packet loss modelled on real network conditions.
This complements our Big Bench Audio benchmark measuring intelligence and Conversational Dynamics (Full Duplex Bench subset) benchmark measuring conversational naturalness. Scores are the average of three independent pass@1 trials. We evaluate under realistic audio conditions using the 𝜏²-bench base task split across three domains:
➤ Airline (50 scenarios): e.g., changing a flight, rebooking under policy constraints
➤ Retail (114 scenarios): e.g., disputing a charge, processing a return
➤ Telecom (114 scenarios): e.g., resolving a billing issue, troubleshooting a service problem
Task success is determined by deterministic checks against expected actions and final database state, consistent with the 𝜏²-bench evaluator.
Key results:
xAI's Grok Voice Think Fast 1.0 is the clear leader at 52.1%, averaging 5.6 minutes per conversation, the second-longest overall. OpenAI's GPT-Realtime-2 (High) (39.8%, 3.0 min) and GPT-Realtime-1.5 (38.8%, 4.8 min) follow, with Gemini 3.1 Flash Live Preview - High close behind at 37.7% (3.8 min).
Speech to Speech is a fast evolving modality and we expect movement in rankings as we continue to add new models with these capabilities, and model robustness improves.
Congratulations @xAI @elonmusk! See below for further detail ⬇️
Show more

year 3 for Anthony Black ✔️
15.0 PTS
3.8 REB
3.7 AST
1.4 STL


Nolan Traore's last four games:
• 17.3 PPG
• 8.0 APG
• 2.8 RPG
• 59.1% FG
• 46.7% 3P


CJ's averages at MSG this series:
29.0 PTS on 54.8% FG
3.0 REB & 3.5 AST
1.0 STL & 1.0 BLK
What's in store tonight?


Czech Republic reported 175 Tesla sales and 0.8% market share in April. BEV penetration is 7.5% and Tesla has 10.4% of this segment. 🇨🇿
• Market share is 0 basis points or 0% above the 3-month trailing average of 0.8%
• 93% Model Y and 6% Model 3
• +3% vs. April last year and +77% compared to January the first month of the previous quarter
• Second best April ever
• 4th best first month of the quarter ever and +77% vs. the previous one
• Best month since 11 months
• Highest first month of the quarter since 24Q4 (6 quarters)
• Last three months +50.8% vs. November - January
• Year-to-date -5% over same period last year
• Year-to-date is 34% or 4.1/12 of last year's total
Show more





NVIDIA $NVDA has missed revenue expectations just once in the last 5 years:
🟢 Q1 2022: $5.66B (+4.6%)
🟢 Q2 2022: $6.51B (+2.8%)
🟢 Q3 2022: $7.10B (+4.3%)
🟢 Q4 2022: $7.64B (+3.0%)
🟢 Q1 2023: $8.29B (+2.1%)
🔴 Q2 2023: $6.70B (-6.9%)
🟢 Q3 2023: $5.93B (+2.8%)
🟢 Q4 2023: $6.05B (+0.7%)
🟢 Q1 2024: $7.19B (+10.3%)
🟢 Q2 2024: $13.51B (+20.9%)
🟢 Q3 2024: $18.12B (+12.0%)
🟢 Q4 2024: $22.10B (+7.5%)
🟢 Q1 2025: $26.04B (+5.9%)
🟢 Q2 2025: $30.04B (+4.5%)
🟢 Q3 2025: $35.08B (+5.8%)
🟢 Q4 2025: $39.33B (+3.1%)
🟢 Q1 2026: $44.06B (+2.3%)
🟢 Q2 2026: $46.74B (+2.4%)
🟢 Q3 2026: $57.01B (+4.3%)
🟢 Q4 2026: $68.13B (+3.9%)
NVIDIA reports next earnings this Wednesday.
97% chance they beat it.
Trade here →
Show more

This chart on Agentic Performance (τ-Voice) provides a snapshot of the current landscape for full-duplex voice models in customer service scenarios. While Grok’s performance is impressive, the fact that the top score is only 52.1% suggests that "AI Agents" still have a long way to go before fully mastering the complexities of human-level customer support.
Key Insights:
• xAI Dominance: Grok Voice Think Fast 1.0 leads the pack significantly with a 52.1% resolution rate, making it the only model to cross the 50% threshold.
• The Competitive Gap: OpenAI’s GPT-Realtime-2 (39.8%) and Google’s Gemini 3.1 Flash Live (37.7%) follow behind, revealing a notable performance gap between Grok and its primary rivals.
• Agentic Evolution: The data highlights a shift from simple transcription to "agentic" capability—the power to actually resolve tasks autonomously.
Show more


What's the latest with Felix lending?
Over the past week, deposits across Felix Vanilla + CDP have grown from $573M to $645M, up by ~12.6%, driven by continued HYPE growth. Stablecoin deposits have remained steady around $95-100M. Borrow demand remains healthy across the platform, with USDC Flagship at 4.32% APY and USDH Flagship at 5.11% APY as of today.
Across Felix Vanilla, borrowing has continued to increase alongside that growth. Total borrows now stand at roughly $122M, with 6.7K active positions across Felix lending markets. Most borrow positions remain well-collateralized, with 4,241 positions above 1.35 HF. Only 104 positions currently sit in the 1.00-1.20 HF buffer range, with collateral at risk of liquidation at roughly $2.9M, or about 0.8% of total collateral.
As far as DaR + CaR today, we monitor debt at risk and collateral at risk through real time scenario testing across the vault suite. Under a 3σ collateral drawdown, modeled DaR is about $1.58M and CaR about $2.15M. Even a 5σ shock remains fully liquidatable. Our DEX + orderbook monitoring makes sure ≤ 3σ swings do not threaten solvency.
Supply utilization across Felix Vanilla sits now over 91% ($122m assets borrowed of $134m assets lent out). If interested in lending to the borrower base on Felix and looking for support, feel free to reach out. More information to come on spot equities borrow/lend.
Show more