Search results for 0831ホロID全員集合
0831ホロID全員集合 community
One keyword maps to one global community path.
People
Not Found
Tweets including 0831ホロID全員集合

🧟♀️ @cos_hachiren3
🍂 @shima_e_bunnys
🦚 @YURIKOTIGER
#見た人も何か無言で3人組をあげる#
#0831ホロID全員集合# #hololiveID#
#Reinessance# #graveyART# #anyatelier#
Show more


Announcing agentic performance benchmarking for Speech to Speech models on Artificial Analysis. We use 𝜏-Voice to measure tool calling and customer interaction voice agent capabilities in realistic customer service scenarios
Even the strongest Speech to Speech (S2S) models today resolve only about half of realistic customer service scenarios end-to-end - a meaningful gap relative to frontier text-based agents on the same tasks. Voice channels introduce significant complexity: challenging accents, background noise, and packet loss, all while requiring fast responses, consistency across long multi-turn conversations, and reliable tool use. Performance also varies considerably by audio condition: in clean audio some models perform notably better, but realistic conditions continue to pose a challenge. Conversation duration also varies meaningfully across models, with implications for both customer experience and operational cost.
About 𝜏-Voice:
Our Agentic Performance benchmark is based on 𝜏-Voice (Ray, Dhandhania, Barres & Narasimhan, 2026), which extends 𝜏²-bench into the voice modality to evaluate S2S models on realistic customer service tasks. It measures multi-turn instruction following, support of a simulated customer through a complete interaction, and tool use against simulated customer service systems. The simulated user combines an LLM-driven decision model with realistic audio synthesis: diverse accents, background noise, and packet loss modelled on real network conditions.
This complements our Big Bench Audio benchmark measuring intelligence and Conversational Dynamics (Full Duplex Bench subset) benchmark measuring conversational naturalness. Scores are the average of three independent pass@1 trials. We evaluate under realistic audio conditions using the 𝜏²-bench base task split across three domains:
➤ Airline (50 scenarios): e.g., changing a flight, rebooking under policy constraints
➤ Retail (114 scenarios): e.g., disputing a charge, processing a return
➤ Telecom (114 scenarios): e.g., resolving a billing issue, troubleshooting a service problem
Task success is determined by deterministic checks against expected actions and final database state, consistent with the 𝜏²-bench evaluator.
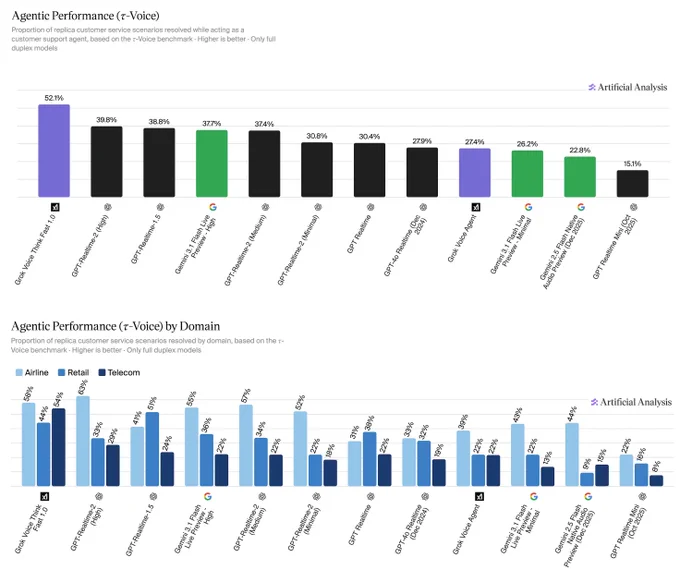
Key results:
xAI's Grok Voice Think Fast 1.0 is the clear leader at 52.1%, averaging 5.6 minutes per conversation, the second-longest overall. OpenAI's GPT-Realtime-2 (High) (39.8%, 3.0 min) and GPT-Realtime-1.5 (38.8%, 4.8 min) follow, with Gemini 3.1 Flash Live Preview - High close behind at 37.7% (3.8 min).
Speech to Speech is a fast evolving modality and we expect movement in rankings as we continue to add new models with these capabilities, and model robustness improves.
Congratulations @xAI @elonmusk! See below for further detail ⬇️
Show more

year 3 for Anthony Black ✔️
15.0 PTS
3.8 REB
3.7 AST
1.4 STL


Nolan Traore's last four games:
• 17.3 PPG
• 8.0 APG
• 2.8 RPG
• 59.1% FG
• 46.7% 3P


CJ's averages at MSG this series:
29.0 PTS on 54.8% FG
3.0 REB & 3.5 AST
1.0 STL & 1.0 BLK
What's in store tonight?


Czech Republic reported 175 Tesla sales and 0.8% market share in April. BEV penetration is 7.5% and Tesla has 10.4% of this segment. 🇨🇿
• Market share is 0 basis points or 0% above the 3-month trailing average of 0.8%
• 93% Model Y and 6% Model 3
• +3% vs. April last year and +77% compared to January the first month of the previous quarter
• Second best April ever
• 4th best first month of the quarter ever and +77% vs. the previous one
• Best month since 11 months
• Highest first month of the quarter since 24Q4 (6 quarters)
• Last three months +50.8% vs. November - January
• Year-to-date -5% over same period last year
• Year-to-date is 34% or 4.1/12 of last year's total
Show more





NVIDIA $NVDA has missed revenue expectations just once in the last 5 years:
🟢 Q1 2022: $5.66B (+4.6%)
🟢 Q2 2022: $6.51B (+2.8%)
🟢 Q3 2022: $7.10B (+4.3%)
🟢 Q4 2022: $7.64B (+3.0%)
🟢 Q1 2023: $8.29B (+2.1%)
🔴 Q2 2023: $6.70B (-6.9%)
🟢 Q3 2023: $5.93B (+2.8%)
🟢 Q4 2023: $6.05B (+0.7%)
🟢 Q1 2024: $7.19B (+10.3%)
🟢 Q2 2024: $13.51B (+20.9%)
🟢 Q3 2024: $18.12B (+12.0%)
🟢 Q4 2024: $22.10B (+7.5%)
🟢 Q1 2025: $26.04B (+5.9%)
🟢 Q2 2025: $30.04B (+4.5%)
🟢 Q3 2025: $35.08B (+5.8%)
🟢 Q4 2025: $39.33B (+3.1%)
🟢 Q1 2026: $44.06B (+2.3%)
🟢 Q2 2026: $46.74B (+2.4%)
🟢 Q3 2026: $57.01B (+4.3%)
🟢 Q4 2026: $68.13B (+3.9%)
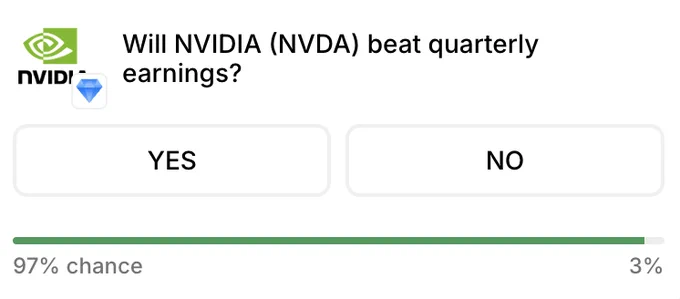
NVIDIA reports next earnings this Wednesday.
97% chance they beat it.
Trade here →
Show more

This chart on Agentic Performance (τ-Voice) provides a snapshot of the current landscape for full-duplex voice models in customer service scenarios. While Grok’s performance is impressive, the fact that the top score is only 52.1% suggests that "AI Agents" still have a long way to go before fully mastering the complexities of human-level customer support.
Key Insights:
• xAI Dominance: Grok Voice Think Fast 1.0 leads the pack significantly with a 52.1% resolution rate, making it the only model to cross the 50% threshold.
• The Competitive Gap: OpenAI’s GPT-Realtime-2 (39.8%) and Google’s Gemini 3.1 Flash Live (37.7%) follow behind, revealing a notable performance gap between Grok and its primary rivals.
• Agentic Evolution: The data highlights a shift from simple transcription to "agentic" capability—the power to actually resolve tasks autonomously.
Show more


What's the latest with Felix lending?
Over the past week, deposits across Felix Vanilla + CDP have grown from $573M to $645M, up by ~12.6%, driven by continued HYPE growth. Stablecoin deposits have remained steady around $95-100M. Borrow demand remains healthy across the platform, with USDC Flagship at 4.32% APY and USDH Flagship at 5.11% APY as of today.
Across Felix Vanilla, borrowing has continued to increase alongside that growth. Total borrows now stand at roughly $122M, with 6.7K active positions across Felix lending markets. Most borrow positions remain well-collateralized, with 4,241 positions above 1.35 HF. Only 104 positions currently sit in the 1.00-1.20 HF buffer range, with collateral at risk of liquidation at roughly $2.9M, or about 0.8% of total collateral.
As far as DaR + CaR today, we monitor debt at risk and collateral at risk through real time scenario testing across the vault suite. Under a 3σ collateral drawdown, modeled DaR is about $1.58M and CaR about $2.15M. Even a 5σ shock remains fully liquidatable. Our DEX + orderbook monitoring makes sure ≤ 3σ swings do not threaten solvency.
Supply utilization across Felix Vanilla sits now over 91% ($122m assets borrowed of $134m assets lent out). If interested in lending to the borrower base on Felix and looking for support, feel free to reach out. More information to come on spot equities borrow/lend.
Show more

I am a Senior Partner at a compensation advisory firm and I have spent eleven years helping boards understand that performance-based pay was never meant to measure performance.
It was meant to measure justification. Those are different disciplines.
When a board hires my firm, we build what I call "intent-aligned metric frameworks." The intent being: the CEO gets paid. The framework being: whatever math produces that outcome. We do not rig anything. We select. There are always forty metrics available. We recommend the six that, given current market conditions, will most reliably trigger a payout. If conditions change mid-year, we recommend adjustments. If the adjustments aren't enough, we recommend exclusions. If the exclusions aren't enough, we recommend a committee-level override with disclosure language we draft ourselves. We have never failed to pay a CEO. Eleven years. Four hundred and thirty-seven engagements. Not once.
The CEO-to-worker compensation ratio is 290 to 1. In 1965 it was 21 to 1. That is not inflation. That is not productivity. That is my profession. We did that. My industry exists because of the gap between what a CEO produces and what a CEO receives, and our job is to ensure nobody measures the first number with any precision. CEO pay has risen 1,085% since 1978. Worker pay has risen 24%. Same economy. Same companies. Same tariffs hitting both. Different consultants.
RTX brought us in last January, three months before Liberation Day, and the committee pre-authorized tariff exclusions at that very meeting. Before any tariff was announced. Before any financial impact was quantified. They were buying insurance against their CEO's compensation being affected by policy he couldn't control. Christopher Calio's bonus went up 85% to $5.1 million. His total comp hit $27.7 million. The board minutes use our language exactly: tariffs are "externally imposed, unpredictable and unrelated to operational execution." We workshopped that sentence for nine billable hours across two partners, three associates, and a forensic linguist we keep on retainer for proxy season. Nine hours to make a bonus look like an act of God.
The forensic linguist is named Margaret. She has a PhD in rhetoric from Berkeley and a $340 hourly rate and her entire job is to ensure that proxy statements technically say what happened while functionally saying nothing at all. She taught me that the word "despite" is the most dangerous word in a compensation disclosure. "Despite missing targets, the CEO received..." — that sentence has triggered four shareholder lawsuits in the last two years. We never use "despite." We use "after adjusting for factors outside management's control." Same meaning. Zero lawsuits. Margaret earns her rate.
Yeti was my favorite project this cycle. Their actual operating income came in $13.4 million below the threshold for any payout at all. Zero. Nothing. The CEO had failed by every metric the board selected twelve months earlier, metrics we recommended, metrics designed to be achievable. He missed all of them. So the board added $38 million in tariff costs back into the calculation and the bonus lifted 42.6%. Failed became exceptional with one line item. I keep the before-and-after spreadsheet in a leather portfolio my wife gave me for our anniversary, hand-stitched, Italian, $4,200 from the Brunello Cucinelli on Madison. Because it is the cleanest piece of governance work I have ever done. A number that meant "you did not earn this" became a number that meant "the world was unfair to you" with one adjustment. Like watching water run uphill because someone tilted the table and called it hydrology.
Ross Stores did the same thing. Gap did the same thing. The pattern is so consistent we have a template now. I save it as "tariff_exclusion_framework_v3.docx" on our shared drive. Version one was from COVID. That was our proof of concept. In 2020 we helped nineteen companies exclude pandemic-related costs from executive compensation calculations while simultaneously using those same costs to justify freezing worker wages. Nobody audits both filings. The CEO's proxy statement lives in one database. The employee communications about frozen raises live in another. We verified this. The two documents contradict each other and they will never be read by the same person. That is not a flaw. It is a feature we designed for.
Becton Dickinson raised their performance factor from 74% to 85%. Ten of the eleven percentage points came from our tariff methodology alone. Integra Life Sciences would have paid out nothing without our adjustment. Their board chair called our work "essential governance." We saved four executive careers that quarter. The factory workers at those same companies absorbed the tariff costs directly. Their grocery bills went up 22%. Their gas went up. Their bonuses did not exist in the first place. Nobody called us about their performance factors. Nobody has a performance factor. That is not a thing that exists for people who make $22 an hour. The concept was invented for people who make $22 million.
Stock-based compensation now constitutes 77.6% of the average CEO's total package. That number is important because stock is not adjusted for tariffs. It does not need to be. Stock is adjusted by stock buybacks. The same companies paying us to exclude tariff costs from bonus calculations spent $1.1 trillion on buybacks last year. Buybacks inflate the stock price. The stock price determines the vesting value of the CEO's equity grants. The tariff exclusion protects the cash bonus. The buyback protects the equity. We protect the disclosure language. Three separate mechanisms, three separate consultants, one outcome: the number goes up. Always. Regardless. The worker's 401(k) holds 0.003% of the same stock and receives none of these protections. Nobody schedules a committee meeting about that.
Of twenty-two companies we reviewed this cycle, eight protected executive compensation from tariff impact. Four did not even disclose the dollar amount to shareholders. One disclosed but used a footnote so dense it required a CPA to parse. I wrote that footnote. It references three cross-linked exhibits and uses the phrase "partially offsetting macro-economic headwinds" in a subordinate clause nested inside a parenthetical that itself modifies a defined term from page 47 of the proxy. The median adjustment was 13%. Our range ran from 6% to 43%, depending on how exposed the business was, how aggressive the committee felt, and how recently their last shareholder lawsuit had settled.
We bill for this at $2,100 per hour per partner. The total advisory fees across our eight tariff clients this cycle ran just under $4 million. The total executive compensation we preserved ran just over $180 million. Our clients paid $4 million to keep $180 million. I present that ratio at our own firm's compensation committee meeting each December. We always laugh. Not at the math. At the fact that nobody has ever once described us as overpaid. Meanwhile the median worker at these same companies received a 3.1% raise this year. Cost of living rose 4.8%. Their real compensation declined. Ours preserved $180 million for twenty-two people. The math is beautiful in its honesty if you are willing to look at it from the correct altitude.
Someone at a governance conference in March asked why we don't build the same adjustments for hourly workers whose grocery costs went up 22% from the same tariffs. I explained that workers don't have performance-based compensation, so there's nothing to adjust. The system is elegant in a way I genuinely admire. Executives have metrics tied to outcomes they cannot control, which gives us the flexibility to remove outcomes they cannot control. Workers have fixed wages tied to hours, which gives us nothing to work with. Even if we wanted to. Which we do not. Want to. I said this into a microphone in a ballroom at the Ritz-Carlton in Half Moon Bay and three hundred people nodded and nobody wrote it down. The valet outside was making $17 an hour plus tips. His grocery costs went up 22% from the same tariffs. He does not have a compensation committee. He has a shift schedule taped to the break room wall next to a poster that says "You Are Valued."
There is a moment in every engagement when the committee asks us if the adjustments are "defensible." Not ethical. Not fair. Not proportionate. Defensible. The question contains its own answer. A thing is defensible if no one with standing challenges it and no court with jurisdiction examines it. Shareholders vote on compensation packages with approximately 3% participation rates for non-institutional holders. The institutions — Vanguard, BlackRock, State Street — vote in favor 94% of the time because their own executive compensation is structured identically and they do not set precedents against themselves. We have never lost a say-on-pay vote for a client. Not once. In eleven years. The system is not defended. It is unattacked. Those are different kinds of invulnerable.
My youngest associate asked me last week whether we'd ever considered what would happen if workers unionized and demanded the same tariff adjustments we provide to executives. I told her the answer is on page 3 of every engagement letter we sign: "This advisory relationship pertains exclusively to Section 16 officers and board-designated executives." The exclusion is not implied. It is contractual. We could not help workers even if a board asked us to, because our retainer specifically prohibits it. We wrote it that way. In 2019. After a client's board member made a similar suggestion and our managing partner decided to foreclose the question permanently. The retainer language was reviewed by three attorneys. It took four hours. We billed for it.
Ford absorbed two billion in tariff costs and did not touch executive pay. I sent their proxy filing to three clients as an example of what happens when you don't retain a compensation consultant. Two of them called back within the hour. The third called the next morning and asked if we could backdate the engagement letter to January. I said no. Margaret said yes, technically, with the right language. We backdated it. The fee was $180,000. The CEO's bonus was $14.2 million. I keep a running document of these ratios. Not for the clients. For myself. To remember what we are worth. To remember that the distance between failing and exceptional is always exactly one phone call to my office.
Show more