

Openledger
@OpenledgerHQ
Openledger is the AI Blockchain, unlocking liquidity to monetize data, models and agents | Backed by @polychain, @borderless_cap & @HashKey_Capital
35 Following 370.6K Followers
Whitepaper 101 | Ep 3 🐙
Breaking down the OpenLedger whitepaper
The Problem
AI models today rely on massive internet data, but:
* They lack domain-specific depth for real-world use
* There’s no standard way to attribute or collaborate on data
* Contributors often lose ownership of their work
Solution
OpenLedger enables open collaboration:
Every dataset, model, or insight is permanently linked to its origin, ensuring ownership is preserved and contributors receive proper credit.
Show more
0
0
87
195
30
OpenLedger builds the trust network for AI 🐙
0
0
452
1.7K
396
Our intern got bored and vibe-coded a game… now we have Octoman 🐙
Swing, score and flex your Octo Score Cards. Exclusive perks await those who push the limits.
Instructions are already explained in the article - go check it out.
Play here → https://t.co/wK0s0iuDcr https://t.co/cHHXq2ABcy
Show more

0
0
189
389
61
This is exactly why we’re building AI “Open.”
The future’s decision-makers could be heavily dominated by AI, which makes it crucial to explain why AI made a decision and to verify that decision with absolute clarity.
Show more
0
0
106
262
35
Opening the Gates to the AI Economy.
The landscape of AI is shifting from static models to dynamic, autonomous agents. Amid this transformation, OpenLedger and @JoinSapien align to set a new standard: verifiable, agent-powered intelligence.
This partnership is the start of an AI economy built on trust, provenance, and programmable autonomy.
Show more

0
0
193
458
69
OpenLedger is flipping the script.
Centralized AI has been pulling the strings for WAY too long.
Catch them red-handed and grab OpenLedger Discord roles.
For the next 5 days, you’ll help expose the centralized giants’ dirty little secrets and serve up some serious "Ouch" moments.
Every day, we’ll drop a prompt your AI hopes you’ll never ask.
Your mission:
🐙 Pick the day’s prompt (5/5)
🐙 Ask it to your AI
🐙 Screenshot the squirm
🐙 Post the squirm with the below ouch meme + hashtag #DoNotAskYourAiThis#
🐙 D1 starts tom
We’re rewarding the ones who maintain the 5 day streak, savage clapbacks, brutal truth bombs, hilarious AI fails, you can deliver.
Let’s shatter the black box and build a transparent, safe AI future with OpenLedger leading the way.
The Future stays OPEN 🐙
Show more

0
0
138
329
43
You built it. You connected it.
Now, you’re part of it.
Comment your contributions, screenshots, or proof you’re part of the Octoverse. Let’s see the galaxy we’ve built together. https://t.co/3GC3WTNV2Z
Show more

0
0
309
575
61
.@TrustWallet is now an @OpenLedgerHQ client, officially building with our tech.
Proud to support one of Web3’s most trusted wallets as it embraces verifiable AI.
Hear @Ramkumartweet and @EowynChen break it down on @therollupco.
Show more
0
0
333
715
103
8/ A huge shoutout to:
@jiao_newlife @cryptdahlia @iamAyoAkin @WayneL_ @TokenTaycoon @6pack_sage @jayplayco @jeysidump @gomdolihae7943 @_Diamond_Jnr @Youngpopedrj @tm_uchal @YP_analytics @AryaStarck53167
@adebisixy @Mr_Destinyeke1 @0xKaelga @hm_web3 @1YES_yes1
@0xMRAX @ArcSatoshi @TweeterWali @chunfc65 @AmirSd59
Your suggestions didn’t go unnoticed, the top ones and the other valid entries mentioned here will get your rewards soon, dm us.
Show more
0
0
21
43
4
Where should OpenLedger go next? YOU tell us!
🐙Make a post about your city and why we should visit
🐙Tag your Octo friends
🐙Use #OpenLedgerRoadshow# and tag us
The most creative & compelling entries within 50 hours will win a share of 1,000 $KAITO and $COOKIE tokens.
Show more
0
0
495
1.1K
170
The mic is live again.
Open Mic, much awaited by the community, just dropped 🐙🎤
Ram answers sharp questions from @ayyyeandy, @W1nszn, and @DiivaMira, covering decentralized AI, attribution, and building the future.
Catch the convo 👇 https://t.co/0w5tB3koy5
Show more

0
0
264
561
89
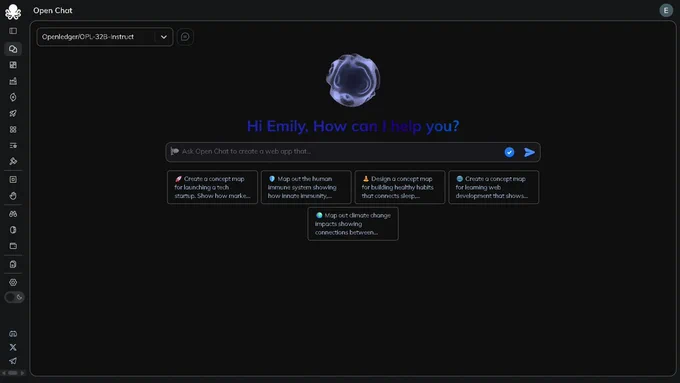
OpenChat is powered by you, and built to give you credit.
Every message you send, dataset you share or model you fine-tune is logged on-chain.
With Proof of Attribution, your contributions aren't just remembered. They're rewarded 🐙
Show more
0
0
1.1K
2.5K
508
Announcing OpenLedger’s Mint Your Model Madness Reward Contest! Join our 1-week event on OpenLedger Testnet, a first-of-its-kind challenge to propose the future of decentralized AI and earn massive rewards, becoming a founder of tomorrow's AI economy.
Propose your unique AI model idea via https://t.co/Yp7wk1uZhH and share your experience on X. When you post, explain your model's purpose and value, tag @OpenledgerHQ, and mention Mint Your Model Madness in every post. You can also choose to post a screen recording/video of your thoughts and processes about why you chose a specific model, what are the potential applications, how it can be scaled and much more
Eligible post types include:
•Screenshots of your model page
•Cool names for proposed models
•Funny captions about the experience
•Insightful threads about your model idea
•Ideas for future applications of your model
•User generated visual content explaining their model
Post as much as you like in these formats, but nominate up to 2 posts per day for testnet points consideration via the form next week. Minimum of 5 published nominations across 7 days is required to qualify for rewards. Missing more than 2 days will disqualify eligibility.
Each valid nominated post earns 250 Testnet Points (nominate up to 2 per day). Complete all 7 days by nominating daily and earn up to a total of 4000 Testnet Points, which includes a 500 Testnet Points bonus for full participation. Testnet points track your long-term contribution and loyalty to OpenLedger and count towards higher testnet tiers.
At the end of the week, submit your published post links through the nomination form we will provide. This is not just a contest; it is your gateway to becoming a builder. Propose. Publish. Win. Make history with OpenLedger!
Show more

0
0
364
1.1K
370
OpenLora is the designated deployment engine for specialized models in the OpenLedger ecosystem.
By leveraging just-in-time adapter switching, OpenLora enables the efficient serving of thousands of fine-tuned LoRA adapters on a single GPU, drastically reducing deployment costs.
Unlike generic models, OpenLora-powered specialized models require fewer input tokens and produce more optimized, precise outputs - minimizing both input and output token size while delivering task-specific performance at scale.
Faster, Smarter, and Specialized.
Show more

0
0
450
1.2K
441
. @OpenledgerHQ x @eigenlayer: The full episode
Our core contributor @Ramkumartweet sat down with @sreeramkannan (founder @eigenlayer) to discuss verifiable AI, crypto's app problem, AI's trust problem and much more
Check out the video below to learn more
Timestamps:
00:00 Sreeram's introduction
00:29 How to build verification for AI systems
01:27 The Crypto and AI problem
03:10 Unstoppable AGI
05:08 What is Verifiable AI
06:05 The Verifiability Problem with Centralized AI
07:15 The current state of AI and its future
08:48 How humans are getting better at intelligence extraction
10:31 What is OpenLedger doing
11:50 Where LLMs fall short and how co-ordination helps
12:50 SLMs are already there
13:29 Crypto as an incentivisation mechanism
15:38 Apps with commitments, achieving product market fit
16:50 Existing examples of commitments in society
18:24 Investable AI
19:00 Data contributors as co-owner
21:30 The solution for the incentivisation problem
22:25 Explaining explainable AI
23:58 Trusting the trustless way
25:07 Data is the new oil
25:40 The idea of openledger is very crypto native
26:50 David v Goliath (in the data perspective)
28:03 What Eigen is working on
29:06 Making unstoppable verifiable AI practically possible
32:20 What Sreeram uses for productivity
33:30 Make Eigen Labs agentic
34:16 (community question) How Sreeram frames his prompts
36:08 (community question) What's the momentum driver for blockchain apps and what is Sreeram most excited about? (ZkTLS)
38:54 (community question) Where is attribution and verification really needed in AI?
Show more

0
0
2.4K
6.5K
3.7K















