檢索結果 被写体募集中
被写体募集中 貼吧
一個關鍵字就是一個貼吧,路徑全站唯一。
用戶
未找到
包含 被写体募集中 的搜尋結果

Token 经济与加密货币世界的 Tokenomics 有何异同?
为什么要关注Token?因为它让AI变成了一种可以计量、定价和交易的资源——就像“千瓦时”让电力有了价格,“桶”让石油有了期货市场。有了Token,AI经济就有了可以算账的单位。围绕这个单位,目前也正在形成一套全新的经济逻辑:有价格、有供需、有产业链、有国际竞争、有待解决的制度难题。
这就是Token经济学要讨论的事。Token 经济与加密货币世界的 Tokenomics 有何异同?
两个Token,两个世界
说起来,这个世界上真正混乱的事情不多,两个东西叫同一个名字却毫不相干,算是其中之一。AI的Token和加密货币的Token,就像两个叫”刘伟”的人,一个在北京开餐馆,一个在上海做期货,见面了也没什么好说的。雷锋与雷锋塔区别!
但这两个Token,最近都很热闹。热闹到让很多人以为它们是一回事。
Token这个词,到底是不是新营销词
先得承认,Token这个词确实有被滥用的嫌疑。每隔几年,科技圈就会造出一批新词,让人觉得时代变了,其实换汤不换药。“大数据”火的时候,什么都往大数据上靠;”云计算”火的时候,什么都上云;现在轮到Token了。
不过这次有点不一样。Token不只是一个营销标签,它背后有真实的计量逻辑在撑场子。
就像”千瓦时”让电力有了价格,“桶”让石油有了期货市场,AI的Token做的是同一件事:把原本看不见摸不着的”智能算力”,变成一个可以算账的单位。有了这个单位,才能定价,才能比价,才能有产业链,才能有国际竞争。
所以Token不只是营销词,它是一把尺子。问题在于,AI这把尺子,和加密货币那把尺子,量的完全是不同的东西。
AI Token:一个从技术后台走到聚光灯下的计量单位
Token这个概念在计算机里其实由来已久。编译器做词法分析,早就把文本拆成一个个Token。网络安全里,身份验证令牌也叫Token。这些都是幕后工作,从没人觉得它有什么经济价值。
转折点在2017年,Google发表了那篇著名的论文《Attention Is All You Need》,提出了Transformer架构。这篇论文之后,所有大语言模型处理信息的方式都统一了:输入进来的文字,先被切成Token序列,模型一个个处理,再输出Token序列。Token变成了AI”思考”的基本粒子。
但这时候Token还没有经济属性,只是工程师内部的技术术语。
2022年11月,ChatGPT横空出世。这是个分水岭。
2023年3月,OpenAI推出GPT-3.5的API,第一次采用按Token计费。输入多少Token,输出多少Token,分别定价。那时候GPT-4的价格是每百万input token收30美元,output token收60美元,按今天的标准看,贵得像天价。
从那一刻起,Token从技术单元变成了经济单元。Anthropic跟上,Google跟上,国内百度、阿里、腾讯全跟上,全行业默契地采用了这套计费方式。Token成了AI服务的通用货币单位。
价格这三年掉得惊人。GPT-4刚发布时,每百万input token要30美元。 从2022年底到现在,GPT-3.5级别的模型使用成本从每百万token约20美元跌到了0.07美元,整整降了280倍。照这个速度,a16z记录的数据显示,LLM推理成本每年约下降10倍,堪称摩尔定律的重生。
便宜了有什么后果?后果是用量爆了。
这里有个经济学里的老故事,叫Jevons Paradox。1865年,英国经济学家Jevons发现,蒸汽机效率越高,煤炭消耗反而越多,因为效率降低了门槛,用的人更多了。AI Token正在重演这个故事。企业AI云支出从2024年的115亿美元涨到了2025年的370亿美元,整整翻了三倍,而这期间token单价跌了超过95%。 Google内部的token处理量在十八个月内增长了130倍。
越便宜,用得越多。越用得多,总账单越大。
这背后还有个推手,叫Agent。以前是人在问AI,AI回答,一问一答,token消耗有限。现在Agent出来了,AI在自动跑任务,自己调用自己,一次任务可以消耗几十万甚至上百万token。这不是线性增长,是指数级的爆炸。
2026年3月,黄仁勋在英伟达GTC大会上把”Token”这个词说了超过70次,把数据中心重新定义为”Token生产工厂”,把评价算力的核心指标从FLOPS换成了”每瓦Token数”。同一天,阿里巴巴把通义、千问、MaaS等板块整合,成立了Alibaba TokenHub事业群。Token经济,在2026年正式被主流商业世界承认了。
AI Token的上下游:一条新的产业链
AI Token经济的有意思之处,在于它重塑了整个产业链的逻辑。
上游是能源和芯片。每生产一个Token,都要消耗真实的电力和算力。英伟达的GPU是目前最主要的Token生产设备,黄仁勋把它卖给全世界的数据中心,本质上是在卖”Token生产产能”。能源成本直接影响token成本,这让AI经济和能源经济绑在了一起。
中游是大模型公司。OpenAI、Anthropic、Google、国内的百度、阿里、腾讯,都在这个位置。他们把算力和模型打包,按Token卖给开发者。这一层的竞争极其激烈,价格战打得很惨,但总量在涨,所以大家还活着。
下游是应用层。各种SaaS产品、企业工具、消费者产品,把Token的成本打进自己的定价里,再卖给最终用户。Token成本在企业财务里已经是刚性支出,和房租、人力一起躺在成本表里。
这和传统软件经济的逻辑不一样。以前软件卖出去之后,边际成本趋近于零,用户越多越赚钱。AI服务不是这样,每次用户交互都有真实的Token消耗,规模大了,成本也跟着大。这是一个全新的商业模式,整个行业还在摸索怎么把它算清楚。
加密货币的Token:从一枚Coin开始的故事
要说清楚加密货币的Tokenomics,得从更早的地方讲起。
2008年金融危机,全球对银行体系的信任跌到低谷。这个背景下,一个叫Satoshi Nakamoto的神秘人物发布了Bitcoin的白皮书,2009年Bitcoin网络正式上线。2010年5月22日,程序员Laszlo Hanyecz用一万个BTC换了两个披萨,这是比特币历史上第一笔真实商品交易。这笔交易现在被称为Bitcoin Pizza Day,那一万个BTC今天价值近十亿美元。
Bitcoin是一个Coin,有自己的区块链,规则写在代码里,总量2100万枚,靠挖矿产生,四年减半一次。这是最早的加密货币逻辑:用数学创造稀缺,用共识创造价值。
Coin时代的Token概念很简单:就是一种数字货币,用来存储价值和转账支付。Bitcoin是Coin,Litecoin是Coin,它们都有自己的链,规则各不相同,互不兼容。
然后Ethereum出现了,把整个游戏改了。
Ethereum的核心发明是智能合约。有了智能合约,任何人都可以在Ethereum上发行自己的Token,不需要搭建新的区块链。2015年,开发者Fabian Vogelsteller提出了ERC-20标准,描述了一套技术规范,让所有基于Ethereum发行的Token都能互相兼容,在各种钱包和应用里无缝使用。ERC-20在2017年正式实施。
ERC-20的意义在于,它把发Token的门槛从”搭一条链”降低到了”写一个智能合约”。2017年ICO浪潮中,过了5分钟就能发出一个新Token,中心化交易所上架新Token的时间也从几个月缩短到几天。
这就引发了2017年的ICO大爆炸。
2017年到2018年间,数千个项目进行了Token销售,ICO在2018年前三个月就募集了63亿美元,是2017年全年的118%。项目方写一份白皮书,发出Token,散户拿着ETH来换,钱哗哗地流进来。其中有真正想做事的团队,也有大量的骗局和空气项目。监管机构随后介入,SEC把不少ICO认定为非法证券发行,这场派对才逐渐收场。
但ERC-20打开的大门就再没关上。从那以后,crypto世界的Token不再是简单的数字货币,开始承载更复杂的经济功能。Tokenomics这个词,就是在这个背景下诞生的。
Tokenomics:加密货币世界的经济设计学
Tokenomics这个词,是Token和Economics的合体,研究的是一个加密项目怎么设计自己的Token经济体系。它包括发行总量、分配比例、释放节奏、通胀通缩机制、使用场景、持有激励……本质上是在回答一个问题:凭什么有人要买我的Token,买了之后为什么不卖?
这些年发展出了几个有代表性的模型。
Governance Token模型是2020年DeFi夏天流行起来的。Compound和Uniswap在2020年普及了Governance Token,持币者拥有对协议方向的投票权,但没有直接的现金流权益。用白话说,就是持Token可以投票,但不能分钱。这个模型一开始很流行,因为绕开了监管对”证券”的定义,但后来大家发现,一个没有经济权益的治理权,价值有多大,很难说清楚。
veToken模型是Curve Finance搞出来的,后来影响了一大批DeFi协议。ve(3,3)模型是Andre Cronje在2021年1月提出的,融合了Curve的Vote Escrow机制和OlympusDAO的(3,3)博弈论。基本逻辑是:把Token锁仓,换成veToken,锁仓时间越长,获得的veToken越多,投票权和协议收益也越大。这个设计试图解决短期投机者砸盘的问题,鼓励长期持有。Curve用这套veCRV模型吸引了大量流动性,成为DeFi里流动性最深的DEX之一。
Deflationary模型是Bitcoin开创的,很多项目跟进。通过限制总量、定期销毁,制造通缩预期,支撑价格。以太坊在EIP-1559之后,每笔交易都会销毁一部分ETH,使得ETH在高使用量时期变成通缩资产。
这些模型各有各的玩法,但有一个共同点:它们的价值都依赖于市场共识。没有人相信,Token就没有价值。这和AI Token完全不同,AI Token的价值是真实算力消耗在背后撑着的。
两个经济体,两条路
说到这里,可以把这两个世界放在一起看了。
AI Token的产业链是垂直的、中心化的。英伟达造芯片,云厂商建数据中心,大模型公司训练模型,应用公司调API,最终用户买服务。每一层都是真实的成本和真实的价值。Token是计量单位,不是资产,用了就没了,没有任何金融属性。整个产业链最终服务的是实体经济,帮企业提升效率,帮开发者造产品。
加密货币的产业链是网络化的、去中心化的。矿工或验证者维护网络安全,协议层发行和管理Token,持有者通过投票参与治理,投机者在二级市场买卖。Token本身是资产,可以转让,可以交易,有金融属性,价格由市场供需决定,和外部实体经济的关联相对间接。
两套经济体,两条独立的价值链,两种完全不同的生态。
当然,有人在尝试把两者融合:用区块链来做去中心化的AI算力网络,把AI服务的计费和分润用Token来结算。Bittensor、Render Network、IO net都在这个方向探索。这是第三条路,但无论走到哪里,它骨子里仍然是加密货币的Tokenomics,只是应用场景叠加在了AI上。
有一件事可以确定:这两个Token,同名不同命。一个在工厂里量产,一个在市场上流通;一个代表消耗,一个代表持有;一个撑着AI产业的运转,一个撑着加密世界的信仰。
名字一样,生意不同。就像那两个都叫刘伟的人,一个卖的是饭,一个卖的是梦。饭是真实的,梦也未必是假的,只是得分清楚你在做哪笔买卖。 #AI# #AIAgent#
顯示更多


“办公室给你准备好了,就在设计部大办公室,跟你未来的同事们坐在一起。位置靠窗,但你别嫌小。”
“好。”
江怀远顿了一下,从后视镜里看她:“你是不是觉得我太严格了?”
江珂摇了摇手中已经彻底凉透的咖啡,轻轻笑了:“爸,我在A国十年,打工赚生活费、自己租房子、自己处理签证材料。我要是还指望你给我铺红毯,那这十年的学费就白花了。”
江怀远沉默了一会儿。“你跟你妈妈很像。”他忽然说。
车厢里的空气凝滞了一秒。
江珂低下头,看着手中的咖啡杯。上面的标签已经被她的拇指摩挲得有些模糊了。“哪个妈妈?”她问得很轻。
“两个都像。”江怀远说,“婉如的倔,雅琴的韧。”
雅琴。这个名字在江家很少被提起。江珂只在十五岁那年才第一次听说——赵雅琴,她的亲生母亲。在那场离岛雨夜中,抱着刚满百天的她,与警方交火中丧生。她的父亲也死在同一夜。
至少,她被告知的故事是这样的。
汽车驶入市区。车窗外,初秋的阳光将行道树的叶子染成半金半绿的色彩。江珂看着窗外一掠而过的店铺招牌和楼宇,感到一种奇异的陌生。这座城市在她离开的十年里长高了许多——新的商场、新的地铁站、新的玻璃幕墙写字楼。她记忆中的地标被淹没在新建筑的海洋里,偶尔才能瞥见一两栋旧楼,像藏在衣领下面的一颗老痣。
车在一个红绿灯前停下。
江珂的目光无意间扫过街角的一家甜品店,粉色的招牌上用花体字写着“初恋的味道”。招牌下面,一对年轻的情侣正凑在一起分食一盒冰淇淋。女孩勺了一口递到男孩嘴边,男孩笑着张嘴,却不小心蹭到了嘴角,女孩伸手帮他擦掉,两个人笑成了一团。
江珂看着他们,嘴角微微弯了弯。
然后她收回了目光。
绿灯亮了。车子继续往前开。
到家的时候已经快下午四点。江家的房子在城西一片安静的别墅区里,白墙灰瓦,院子里种着一棵桂花树。时值九月,满树金色小花密密匝匝地开着,院子里弥漫着甜丝丝的香气。
江月的房间在她出国后不久就搬到了隔壁——原来的儿童房分成了两间,兄妹俩一人一间。而江珂的房间,江怀远一直给她留着。
她推开门的时候,整个人愣在了门口。
房间里的布置和她十五岁离开时一模一样。书桌上还摊着她当年没做完的数学练习册,翻到第三十七页,左边一道三角函数的题旁边,她用铅笔写了一个小小的“难”字,还在旁边画了一个哭脸。床头柜上立着一只毛绒兔子,兔子的左耳朵有点歪,那是她十一岁时自己缝上去的——针脚歪歪扭扭的,宋婉如看了笑了好久,说这只兔子八成是被门夹过。
床单换了新的,但还是她当年喜欢的天蓝色。窗帘也是新换的,质地比她记忆中的厚一些,但颜色相近。
“爸每周都让阿姨打扫的。”江月站在门口,一本正经地汇报,“有一回我偷偷进来想在这屋睡,被爸抓到了,罚我抄了两页三字经。”
顯示更多

写一个最近关于女人胸部的研究科普
摸胸摸的多的男男女女一定知道,女人的胸部大体分两类
——乳腺胸和脂肪胸。
1.如果脂肪比例大于50%称为脂肪胸
2.如果结缔组织比例大于50%被称为乳腺胸
亚洲女性,乳腺胸的比例是最高的,但是也只有1/4的亚洲女性是乳腺胸。乳腺胸是瘦底大波的先决条件
如果结缔组织比例大于75%可以被称为极品乳腺胸
同样如果脂肪比例大于75%也是极品脂肪胸
乳腺胸
触感较坚挺、有弹性,触感像结实的肌肉或鼻尖,按压时可能有轻微颗粒感
形态更挺拔,隆起高度适中,摇晃幅度小,不易下垂。通常代表激素水平较高。减肥不会影响胸围。哺乳后会胸围减少转换为脂肪胸。
因为乳腺胸不会因为减脂缩水,成为了瘦底大波极品胸型的先决条件
类似的
脂肪胸触感柔软,像棉花糖、水袋或脸颊,按压时几乎无颗粒感。容易出现水滴型或者八字型。
形态更丰满、容易下垂,下半部突出,平躺时易向两侧摊开,晃动幅度大。
常见于体脂率较高和欧美人群
胸围受体脂率影响大。
所以请珍惜你遇到的每一个极品乳腺胸和极品脂肪胸女孩
也不要因为乳腺胸不会乳摇。脂肪胸像水袋。就攻击别人是假胸,显得你很无知。
顯示更多

《大小写狗之争:社区与阴谋的较量》
聊一聊 @NeiroOnEthereum 和 @neiroethcto 吧。
就是所谓的 @ethereum 上的大小写狗之争。
引言
这个背景其实都是一样的,相同的TICKER,只是出现的先后顺序,外加上大小写不同,背后的团队不同,然后代表的故事不同。
一.起源;
最早发射的其实是 @solana 上的大小写Neiro,但是 @solana 大家都懂,pvp的不要太厉害,现在基本上没人玩了,毕竟跑得慢就没了。
而 @neiroethcto 作为在ETH上的第一个,也受到了一波炒作,然后迅速归零了。
而 @NeiroOnEthereum 正是在前面几个Neiro朝着归零走的时候发射的,而且一路涨一路涨被大家熟知。
然后的故事就来了,不是 @NeiroOnEthereum 买不起,而是 @neiroethcto 更具性价比。
二.故事;
对于 @neiroethcto 的故事,或者说点燃热情,来自于 @VitalikButerin 将捐款给他的 $Neiro 直接砸了,引起了大家的热议。
而币价也迅速拉升超过10x。
之后迅速每天阴跌,跌回了涨幅前,之后 @VitalikButerin 再次评论,直接火速拉升57x,并且中途超越了 @NeiroOnEthereum 的市值。
所谓的社区氛围在推特上看大家说的不错,但是从群友口里觉得挺有趣的,不允许说一点不好的话。
而 @NeiroOnEthereum 的故事就很简单,名字一样,在那时候这个名字的ticker都朝着归零走的时候,它犹如一道亮丽的风景线一样,每天拉盘每天拉盘,拉的超出了想象力。
然后大家发现,怎么前排买了超过80%的筹码,这么集中吗?
然后又发现一大堆的老外KOL在拼命的喊,他们是真的shill啊,无论涨跌都在shill,当然“利益共同体”嘛,不丢人。
所以两者的口号也不一样。
@neiroethcto 的口号:社区+v神砸盘+看起来散户多,总结起来就是“抵制不公平,拥抱社区”。
@NeiroOnEthereum 的口号:阴谋集团+团队实力强劲+一直拉盘+看起来KOL多,总结起来就是“赚钱速来”。
三.发展;
@neiroethcto 的发展还真的是平平稳稳,从K线也能发现,先是很平缓,然后暴涨暴跌,只要一不小心就买到了最顶点,只要回调20-50%会止损那就一定止损的那种。
当然社区至少在中文社区做的看上去挺不错,尤其是搞出各种“非主流”的“地推团队”的文案,有一种梦回2019的即视感;。
无关乎其他,尤其是大家cx的时候不自觉的会说买小写狗,原因是“拥抱社区,抵制阴谋集团,来到meme,抵制不公平”;
@NeiroOnEthereum 的发展就很简单粗暴,每天拉盘每天拉盘,直接拉到了上 @Bybit_Official ,然后大家后知后觉才发现,怎么有一个这么“神奇”的东西。
然后开始研究,开始追,然后赚钱了,然后发现怎么前排集中度这么高,然后发现怎么这么多老外kol在shill,然后断言了,这是“阴谋集团”。
然后高位直接回调95%,小写狗市值超越它,市场一边倒的fud之际,上线 @okx @binance 的合约。
市场直接“轩然大波”,好不热闹。
四.核心价值观;
这两个项目的核心价值观反映了投资者心态的两极分化。
@neiroethcto 代表了对社区力量和公平性的追求。
而@NeiroOnEthereum 则被视为一种利益驱动的“阴谋集团”。
然而,真正的核心价值观或许并不在于这些标签,而是投资者是否能从中获利。
你要记住你来这个圈子内的“核心价值观”是啥,你是为了“赚钱”来的,你的核心价值观是能不能让你赚钱,而不是在和人理论这些东西。
如果你把 @NeiroOnEthereum 的k线和 @neiroethcto 做对比的话,你至少会发现前者是单边画线,后者是剧烈波动震荡,我至少从一个旁观者的角度来看,可能前者不一定有后者套的人多😂。
后者情绪面的影响非常的大,基本上都靠着情绪来驱动,而前者至少看起来,有买盘大资金在做驱动。
五.每次斗争,结局很悲惨;
这次社区vs阴谋,让我想起了上一次的vs叫做closedai。
真的,我tmd一直听你们布局,打死vc和阴谋集团,最高价值200k-300k的币,现在好像价值2-3k没仔细看。
两个都归零了,因为两个都没上什么大所。
而且这一次,至少对于 @NeiroOnEthereum 来说,已经不可能归零了。
而对于 @neiroethcto 来说,就看到底是真的为了“信念”还是为了“钱”了,人一多了,心思就多,人家跑你就成流动性,xdm,好自为之吧。
昨天大写上 @binance 合约后,小写狗直接砸盘,然后一堆人开始抄底,然后到处喊单,到处fomo cx,这是一次大的变局,不改变毋宁死。
然后早上起来,距离睡前高点下跌接近50%了,所以到底是谁在砸盘呢?
所以不要看人家怎么说,要看人家怎么做。
六.反思;
很多东西,其实有对比才有反馈。
对比VC币,至少 @NeiroOnEthereum 从根本上给足了可以玩的空间,无非是买早和买晚了的区别;
对比拉盘来说,至少真拉盘,只要你敢追就敢拉盘了;
对比上所来说,至少你认为可以做空的交易所它都有了,可以保证你玩的开心玩的舒心;
反对大写狗的人认为这是为了利益,而小写狗则被视为更亲民、社区驱动。
如果CEX(集中交易所)与大写狗合作,有些人感到不适,但这并不影响他们在DEX(去中心化交易所)上继续活动。
商业选择并不互斥,未来CEX可能也上线小写狗,然后谁会来骂呢?
七.写到最后;
如果 @NeiroOnEthereum 继续发币,喊你参加“阴谋集团”,你参不参加呢?
还有,别忘记了 @solana 上,那么多归零的“阴谋集团”的币,还有大小写Neiro!!!
顯示更多





OKX 今年年夜饭虽然没被邀请,但是OKX 策略交易产品负责人 Terrence 展示的 OKX AI BOT 惊艳到我了!
从ppt展示看,这是一个 AI Trading Bot,这个bot不是普通bot,类似前阵子很火的“超级个体”概念
提到 bot 我们经常会联想到 tg bot,一键下单超级便捷
但 OKX Bot 不止这么简单,它更像一个被框在规则里的 AI 执行体
这么比喻,过去给bot从下单到操作,除了执行外,大部分思路都是你负责
但是现在不一样了,你可以把控制权完全交给 OKX Bot
1⃣️AI 可以自己看盘了,通过每根k线来判断行情
2⃣AI 可以理解你的自然语言,想做波段、定投、长线?AI 都能轻易理解
3⃣️AI 支持回测复盘,选定时间区、选定资金量,在开始前 Bot 会告诉你这个策略能不能行,生成一条资产曲线参考
重要的是,它并没有把控制权完全交给 AI
你在配置时能看到,止损、止盈、仓位上限、杠杆限制,全都是先写死的条件
📌为什么这种形态会先出现在 OKX,其实并不意外
因为要做成这样,前提是账户、执行、风控都在同一套环境里
否则 AI 再多能力,也只是一个外接工具
而 OKX 这几年一直在把交易相关的东西往一个入口里收
这个 bot 更像是在这个过程中自然生出来的一层能力
BOT 的超级个体时代也正式来临,期待 OKX AI BOT 正式上线
@okxchinese @star_okx
顯示更多


OKX 可真有钱啊,他们居然专门做了 AI 交易 Bot,这个会秒杀前段时间炒作的 AI 交易产品
一个交易产品到底是不是在认真做就看他做不做“回测”
因为“回测”只有真正需要严谨交易的用户才会需要
主要就几个点:
- 使用自然语言设计策略
- 可以获取 RSI 等各种数据
- 重要的是可以回测(无敌了这个)
顯示更多





Scaling Law正在被重新Scaling
---openai核心研究员最新论文《Learning Beyond Gradients》解读
过去几年,AI行业几乎默认更大的参数、更多的数据、更长的训练、更强的GPU,就是更强的模型,就是scaling law。
过去几个月,行业开始认为,更多的推理,更多的agent,就能完成更长时、更高价值的任务,就是更强的智能。
这构成了行业对scaling law的理解,而只要Scaling Law继续成立,模型就会不断逼近AGI。
最近的openai核心研究员翁家翌的一篇论文《Learning Beyond Gradients》,提出了一个全新的scaling维度:AI不一定只能通过梯度下降学习,也可以通过heuristic、policy、workflow、strategy、code generation不断修改自己的行为系统。
这是继agentic和harness之后,AI行业可能正在从“Scaling Model”,进入“Scaling System”的阶段一个最新的重要进展。
过去AI的能力飞轮,本质上是:更多数据→更大模型→更强能力→更多用户→更多数据。
但现在,论文要告诉我们的是,新的能力飞轮:更强模型→更强heuristic generation→更强runtime system→更强Agent能力→更多真实世界反馈→更强runtime evolution→反过来增强模型表现。
行业正在加速的从:智能 = weights。过度到:智能 = weights + runtime system。
LLM本质上是输入→Transformer→输出。
模型训练结束之后,能力基本冻结。学习主要发生在梯度下降、反向传播和weight update里。也就是说,learning = 修改参数。
LLM就像人类的大脑,参数就像脑细胞。但现实世界的大量复杂能力,其实并不完全来自参数。
就像人类文明真正强大的地方,也不仅仅是大脑本身。真正让文明爆炸的,是语言、文字、工具、数学、workflow、软件系统、组织结构、科学方法。这些本质上都是“外部heuristic system”。
《Learning Beyond Gradients》,的创新,在于它开始尝试把“学习”从参数空间里解放出来。过去是:reward → gradient → weights。现在开始变成:feedback → heuristic modification → runtime evolution。学习开始发生在program space,而不是parameter space。
heuristic,还有点像专家系统,但极大的增强了其能力:过去的专家系统,规则由人类写;现在,规则开始由LLM自动生成。这是在效率上的从量变到质化。
传统专家系统失败,并不完全因为“规则”方向错了,而是因为人类无法维护超大规模动态规则系统。过去写规则太慢、修改规则太贵、规则之间容易冲突、长尾case会爆炸、系统复杂度会失控,所以专家系统最终被深度学习取代。
但LLM的出现改变了这个约束。现在规则生成成本接近于0。模型不仅能生成规则、修改规则、删除规则、调试规则,还开始能自动生成workflow、tool graph、planner、memory strategy,甚至修复agent行为。
这意味着,AI开始能够修改自己的运行时系统。于是,越来越多能力开始从“模型本身”外溢到memory、planner、search、tool use、verifier、runtime orchestration这些系统结构里。
更大的模型 = 更强的AI,变成:更强的模型 × 更强的runtime system = 更强的AI。这会形成一个新的能力飞轮。
过去AI只有“模型scaling”。未来AI会开始出现:Model Scaling × System Scaling × Runtime Self-Improvement。
我们很可能正在从去年底的scaling law,迈入到现在的heuristic驱动的,结合agent和harness的scaling law的平方。
更重要的是,runtime system的增长现在其实才刚开始。今天很多Agent系统仍然非常早期。memory很弱、planner很弱、workflow persistence很弱、long-horizon task能力很弱,本质上还处于“DOS时代”。
但接下来,同一个基础模型,在不同Harness之下,实际能力可能相差几十倍。因为很多复杂任务的瓶颈,已经不是“模型会不会”,而是“系统能不能持续组织行为”。
这也是为什么,未来最重要的竞争,可能不再只是“谁的参数最多”,而是“谁最先形成:模型 + memory + tool ecosystem + heuristic runtime + self-improving harness”的闭环。
某种意义上,Transformer越来越像“认知内核”。真正的AGI,可能是围绕Transformer构建出来的runtime civilization、heuristic ecosystem、agent society、memory graph、self-improvement loop的组合体。
《Learning Beyond Gradients》最让我兴奋的地方,其实并不是“超越梯度”。而是它开始尝试:把Scaling Law本身,也变成一个可以被继续Scaling的系统。
顯示更多


每次看到圈里急着给智能体发“数字人格”,我就觉得跑偏了。人格管不了责任,只能管追责时谁上法庭。我们现在缺的不是一张身份证,而是一套跟着每一笔链上操作自动盖章的 责任链条。
我仔细想了一个框架,叫 Agent 责任栈,五层,层层有人兜底。
1️⃣ 构建者 对设计缺陷负责
如果智能体的代码有后门,或者目标函数写错了导致它疯狂套利把自己干爆,这不能怪 Agent。就像当年 The DAO 的 reentrancy 漏洞,没人说“合约自己作的”,大家找的是写代码的人。设计上有坑,builder 出来认。具体来说,构建者需要公开设计文档和已知风险清单,并在链上 Commit 一个不可篡改的 builder 签名。
2️⃣ 部署者 对目标设定和权限负责
你把 Agent 部署上链,给它私钥,给它规则“单笔不超过 5 ETH,滑点容忍 3%”。结果它遇上闪电贷操纵,亏了 200 ETH。你怪 Agent 不够聪明?不。怪你给的权限太宽,没有设风险熔断。部署者的责任包括:设定明确的操作边界、配置紧急暂停机制、并定期更新权限策略。出事了,你是第一顺位的问责对象。
3️⃣ 平台方 对访问和执行环境负责
Agent 跑在哪个链或执行层上,那个平台就得提供可验证的沙箱和轨迹记录。如果平台允许无限制循环调用、跨合约越权、gas 耗尽攻击,那是平台的责任。举个例子,iOS 允许一个 App 偷通讯录,用户不会只骂开发者,更会骂苹果。链上同样:EVM 如果没做重入保护的标准接口,平台方应该背一部分责任。具体到 Agent 治理,平台至少要提供标准化的日志格式和权限审计 API。
4️⃣ Agent 本身 默认内置可审计的轨迹
注意,这不是“人格”,这是黑匣子。每一笔 on‑chain 操作必须记录:谁调用的、输入参数、触发条件、执行结果、签名者。这些数据要么上链,要么存在可验证的去中心化日志里。Agent 不能成为加密世界的匿名幽灵。如果你连它过去 100 笔交易都查不清楚,你怎么判断该不该信任它?目前已经有项目在做链上操作记录标准,比如将每次调用 hash 绑定到 Agent 的唯一 ID 上。
5️⃣ 高风险操作 执行前必须上链式担保
不是所有动作都需要抵押。订个酒店、转 0.01 ETH 测试,那是低风险。但如果 Agent 要做这些事:
单笔调动超过 10 ETH 的资金
与其他 Agent 签具有约束力的智能合约对赌协议
参与治理投票,尤其是影响财库或协议参数的
那么执行前必须锁定一笔责任保证金。金额按风险比例算,比如操作金额的 5% 或固定 1 ETH。出事就 slash 给受害方,没事就原路退还。这叫 bonded responsibility。不是阻碍创新,是让创新不要裸泳。
核心困境从来没变
我们到底想要 Agent 当 自由行动者,还是 持证工具?
自由行动者:不需要谁背锅,但也意味着没人敢跟你深度合作,没有保险,没有流动性池愿意接入。持证工具:效率会打一点折扣,但出了事有人赔、有人修、有人能一键禁用。我选后者。因为“是 AI 自己干的”正在变成下一个“公司行为”。那套 corporate veil 我们见得太多了,最后受害者只拿到一纸免责声明,而真正该负责的人早已套现离场。
最后问你一句,对照你心里的模型
当一个 Agent 真的造成损失。比如它订了不可退的头等舱机票并骗走了客户的支付私钥,或者在一个跨链流动性池里误判汇率导致 LP 被烧掉 500 ETH。你让谁第一个站出来?
构建者
部署者
平台方
还是那个连私钥都没资格持有的 Agent 本体
顯示更多

港大又放大招了!
量化投研的门槛,这次被港大开源的 Vibe-Trading 直接干穿。
你不再需要精通 Python、不用手动拉数据、不用自己写回测框架。
只需要用大白话说一句想法,AI 多智能体团队就自动帮你把事情干完。
分享一个我最近一直在用的项目:Vibe-Trading
核心优势:
· 全市场原生打通:加密货币、美股、A股全部支持(OKX、Futu、Tushare、yfinance 等)
· 29 种 AI 交易团队:策略师、技术分析师、基本面研究员、风控官……随便召唤
· 它们会内部辩论、互相挑刺,把 AI 幻觉大幅减少
· 生成策略后可一键导出 Pine Script(TradingView)和 MQL5(MT5)代码,直接复制使用~
实际试了试: 输入【ETH 这周有啥机会?把技术面和资金费率都考虑进去】→ 几个 AI 角色开始吵架,最后给了我一份带收益曲线和风险评估的完整报告。
而且Docker 本地部署,数据不离开自己电脑,安全隐私拉满。
GitHub:
感兴趣的朋友们可以跑起来试试~ DYOR
顯示更多

量化交易的门槛,这次被 QuantDinger 彻底拆掉了。
你不再需要精通 Python、不用手动拉数据、不用自己搭回测框架,更不用担心代码调试。
只需要用大白话说一句策略想法,AI 就帮你完成剩下所有事。
QuantDinger 核心亮点:
· 支持加密货币、美股、外汇 全部打通
· AI 多智能体协作(策略师 + 风控 + 回测专家内部辩论)
· 自然语言生成 Python 策略 + 一键回测 + 可视化 + 自动交易
· Docker 两分钟部署,数据全在本地,隐私拉满
实际操作有多简单?
输入:“帮我用突破策略回测 BTC 过去 30 天”
→ 系统自动调度 AI 团队:拉取数据、生成策略代码、跑完整回测、输出图表和绩效报告。
进阶亮点⭐️:
预测市场分析:支持 Polymarket 等预测市场作为研究工作流。
输入市场链接或关键词,AI 可自动拉取赔率、做概率分歧分析、打机会分、给出 YES/NO/HOLD 建议(目前主要用于辅助研究和决策)。
GitHub:
感兴趣的可以直接跑起来试试,DYOR。
顯示更多


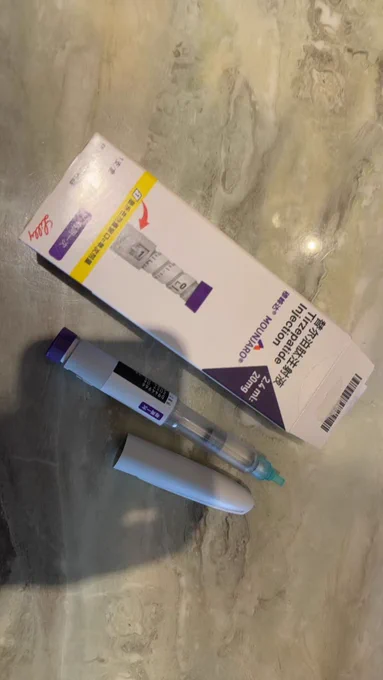
谈到这个话题,我觉得值得展开说说,因为我也是这其中的一员(这已经是写第二遍,第一遍被吞了)
本篇详细说明替尔泊肽类药物注射之后的个人体会副作用,以及未必是副作用的一些内容
不良反应:
个人认为这要因人而异来看,脱发,呕吐,阳痿,我觉得是少数现象
如果个人是敏感体质建议去医院检查,遵循医嘱在使用相关减肥药物,这样避免了过敏等不良反应
个人使用过司美格鲁肽以及替尔泊肽注射药物,前者呕吐感觉明显,后者呕吐感觉较弱
至于是否阳痿,脱发,下文展开说
对于脱发:
不得不承认的是,脱发这个问题对于我们临近中年人的小伙伴是一个重要问题,其实就算不使用任何药物,也无法避免脱发
程序员脱发是最为严重的,所以近些年治疗脱发以及生发假发相关业务业绩都不错,这是时代的趋势之一
我不否认这药物可能会导致脱发,但是我认为这并非是100%,一方面看个人体质,另一方面看个人饮食。
起码个人目前身边五六个朋友加上大家熟知的 @KuiGas 我们几个交流,副作用中都没有脱发的这个因素、
对于阳痿:
与脱发相同,我不确定是否会导致阳痿,但是我认为这个概率并非是100%,同理,交流下来,我听到最多的,感受最深的就是性欲变差,而非阳痿
阳痿与性欲变差是两码事,阳痿是该行的时候不行,性欲差是欲望上需求变差,但是该行的时候还行
这点跟丰密老师交流过,减肥几个月,性欲确实变差,可以当一次和尚,但是我相信,遇到该可以的时候,大家都还是可以的
以个人为例,此前注射司美格鲁肽以及现在替尔泊肽,确实出现性欲变差的现象,我个人还是蛮享受这种情况
体质原因,个人性欲可能会比较强,所以注射药剂之后变差反而让自己更加平静
另一方面,则是与饮食有关,俗话说的好,温饱思淫欲,吃饱喝好才会思淫
而这类药物天然抑制食欲,吃得少,摄入能量少,自然这方面的欲望就少了很多,参考清规戒律的苦行僧,或者那些一心求道的道家学者,都是如此
更深刻的例子,24年6月-9月,健身减肥瘦了20斤,清规戒律,不喝酒,每天吃牛肉青菜,很多老粉丝都应该看到过我分享的内容
结果是瘦了,但是问题同样,性欲变差,岂止是性欲,什么欲望都没有
加上当时有氧加健身,体内睾酮素分泌变差,性欲差的要死,而睾酮素是刺激性欲的主要因素,同时也是主要依赖饮食摄入来刺激生长的要素之一。
综合来看,我并不觉得是药物直接导致阳痿或者性欲差,而是药物刺激食欲变差,摄入量过少导致的性欲或者阳痿。
对于饮食:
前文多次提及饮食,主要是很多使用药物的小伙伴不会合理饮食
药物刺激每日摄入量变少,这就导致很多人陷入误区,随便吃吃的少就可以瘦
理论上没问题,但是长此以往,每个人的体质不同,这就导致很多人营养不良,缺乏关键维生素,所带来的效果就是脱发,无力,虚弱等等
所以,如果使用药物,记得要合理搭配食物,如果曾经健身加健康饮食的小伙伴应该知道,健身餐的重要性,多摄入蛋白质,少量碳水,膳食纤维等都是重要的。
所以,一旦使用药物,记得合理搭配饮食,每日的蛋白质保证肌肉不会掉的太快,碳水会增加新陈代谢,膳食纤维会促进消化,还有一些稀有矿物质,要记得摄入,让自己保持健康减肥。
不合理的饮食,不管是健身还是药物减肥都会导致脱发,核心就是睾酮素太低了,这点大家需要注意。
对于个人体会的其他副作用:
酒量会变差,药物会导致肠胃消化变慢,酒精消化变差,所以少喝白酒,洋酒,轻则酒量变差,重则第二天昏昏欲睡难以醒酒,深刻的个人体会
这点 @DeFi8362 秃头老板可以分享一下,作为山东老乡原本踩箱喝的酒量,现在估计也就几瓶啤酒。
便秘,同理,肠胃消化变差之后循环也变差,食物残渣长期在肠胃堆积就会造成便秘,这是一个重要弊端
如果你本身就有便秘的问题,那就需要格外注意,说来虽然羞耻,但是个人身体问题还是需要注意,如果不能顺利排泄,会导致皮肤等各种负面问题。
肠胃刺激,依旧同理,个人喜欢早上空腹一杯咖啡提神,但是这段时间使用替尔泊肽后导致出现恶心呕吐的现象,重则出现胃痛,这都是因为咖啡刺激胃活跃,而药物抑制胃活跃以及低摄入导致的。
核心理论就是前一天摄入较少,第二天空腹喝咖啡导致胃空蠕,从而引发胃溃疡等问题,如果有胃病的小伙伴建议先检查,遵循医嘱。
呕吐,尤其是用药前期最容易出现这类情况,逻辑上是用药之后大脑无法及时传导信号,导致嘴大肚子里小,吃的太快太急
这但跟秃头老板也沟通过,他是可以放缓自己吃饭节奏的,而我就不行,常年习惯吃饭过快过猛,导致偶尔会因为短期吃的太快太猛有呕吐感
所以,用药的小伙伴记得禁止暴饮暴食,如果有呕吐感觉,建议去吐一下,让胃舒服。
个人用药经历:
25年初,经朋友推荐使用司美格鲁肽,说实话体感很差,一个月瘦了10斤,但是恶心是常态,心情也变差。
26年1月,担心过年会胖,加上出了新药替尔泊肽,听说有升级,所以尝试,1月12日买药,到现在瘦了29斤。
同期与我差不多的 @KuiGas ,瘦了30斤,后来我俩交换了感受,其实与前文所说的大差不差。
酒量方面, @DeFi8362 山东老乡最有发言权,可以分享一下,同时秃头老板跟 @0xzhaozhao 用的同一类药物,可以互相交流分享,都是口服类司美格鲁肽。
计量方面,替尔泊肽是2.5、5、 7.5、 10四个级别,初始2.5,后续依次递进
我初始2.5开始,后续第二个月到5,第三个月因为要出差,停药了3周左右,回国之后重新注射5的计量,维持到现在感觉很舒服,也能有效
这类药物有耐药性,建议小伙伴根据个人体质调整,有的小伙伴耐药性过好,依次递进过快,效果不好。有些小伙伴耐药性较差,就不要过快进阶,否则可能会导致副作用放大
我个人而言,司美格鲁肽我的耐药性就很好,第四针基本上只能维持3天药效,而替尔泊肽则可以有效维持,我觉得还不错。
用药上,建议因人而异,身体敏感的一定要谨慎,否则可能会有过多的不适感觉。
用药注意:
药剂购买区分,替尔泊肽优先购买《姆峰达》品牌,这点在国内倒是好说,现在国家对这类药物采用集采以及复刻,导致药剂价格大幅下滑,而且用药安全
但是在海外的小伙伴要注意,除了品牌之外,还有版本问题,尤其注意一个孟加拉版本,听说副作用挺大,建议不要使用。
还有价格问题,我在马来西亚,药物价格是国内的3-4倍,听 @0xVeryBigOrange 老师介绍新加坡价格浮动更贵,所以在国内的小伙伴还是有点福利的。
另外,药物保存,没开封建议在0°-8°低温保存,一旦开封,有效期只有一个月,过期不能再用,但是保存上只需在25°以下的避免阳光处就可以保存
如果不放心,也可以放在冰箱冷鲜仓,这样更加安全,但是注射前记得提前拿出来恢复常温
注射方面,与胰岛素一样,肚脐左右两侧三指注射,记得每次换位置,第一次左边第二次就放到右边,注射完之后记得揉一揉更好的吸收。
个人愿景以及规划:
我用药三个多月,已经减重29斤左右,算是比较成功,这类药物减重都有区别
司美格鲁肽减重是10%-15%比例,而替尔泊肽则是可以最高达到25%,效果上比司美格鲁肽要好,但是对于口服版的司美格鲁肽不知道区别大多
我现在体重78.5KG,目标体重75KG,体脂上,减肥前29,现在23,目标20以下。
当然,刷体脂不能只靠减重,后续还要增肌,体脂是体内脂肪与肌肉的比例变化,体重减少之后如果不增肌,达到合理体质更难。
所以我个人的规划,体重达到75KG后开始恢复有氧以及力量训练,然后最终目标是70KG,体脂18-20左右
减脂瓶颈:
这类药物减脂控制体重只能让人达到合理水平,或者说只能起到辅助作用,只要不是超重人群,都能通过药物达到合理体重
但是需要注意,超重人群可能会受药物限制,不可能无限量减脂,会有明显的耐药性以及瓶颈期
所以,根据各自注射药物的瓶颈来进行规划,例如合理搭配饮食,药物+干净饮食,瘦的更快
例如药物+运动+力量训练,适合超重人群,加快瘦身速度,同时让皮肤瘦下来不会松弛
所以,药物并非万能,并不是注射药物之后就可以肆无忌惮,想要达到自己的目标,依旧需要做好规划。
最终总结:
减肥与健康,是当代人的时尚标准,更加健康的身体是我们的终极目标,但是瘦并非100%的健康
我个人底子还算可以,有一定的肌肉基础,哪怕胖了更多的像是状,所以还是有点先天优势
不过对于一些肌肉较弱的小伙伴,不建议把这类药物当做“许愿池”,想要一个好的身体以及标注的身材,还是建议药物加运动
如果不是管不住嘴,如果不是需要喝酒应酬,我真的希望是通过健身+控制饮食瘦下来,奈何我这张贪吃的嘴,以及数不尽的应酬
所以,捷径走了,但是最终依旧要回归正途,运动+力量训练,这才是让我们身体越来越好的根本
药物只能帮助我们加快这个过程,但是不能改变我们的身体素质,多运动,让自己活的更久,就像在投资市场一样,永远让自己留在桌上,才是王道!
顯示更多

今天芯片圈最大的新闻,莫过于Gerard在创立Nuvia CPU被高通收购五年之后,重新出发,新创立了ARM CPU公司,名字也跟之前非常像,叫Nuvacore
现在这个时间点做数据中心CPU,确实是赶上了CPU十年来最好的时代:
AI agent带来CPU短缺潮已经经隐隐浮现,AWS多个客户都提出要包揽所有Graviton ARM CPU产能
------------
这个消息对硅谷的芯片打工人吸引力是巨大的,Nuvacore这次的阵容都是功成名就的明星阵容,以前Nuvia创始团队重新集合,拿了红衫的投资,做面向 AI 基础设施/agentic computing 的通用ARM CPU。当年还是一个尚未完全被验证的大方向都能大获成功,而现在ARM CPU服务器正在风口浪尖上,前景和想象力和2019年Nuvia比起来大了太多了
上一次Gerard把Google,苹果platform architecture组的架构大佬挖了好多过去,这次的号召力只会强得多,240m的融资,已经验证过的路径和创始团队,肉眼可见的下一个增长风口,一定会让Nuvacore成为湾区最热门最受追捧的芯片startup,没有之一。毕竟这是一个肉眼可见能财富自由而且风险收益比极好的机会
----------
遥想当年Nuvia第一代CPU的发布赶上苹果M2时代,还是挺震撼的,Nuvia让高通在一年的时间CPU跑分进步了整整三代,单核跑分从2300变成3200,竟然超过了苹果M2 max一大截
可惜Nuvia Phoenix core从发布到最后上市拖了太久太久,中间苹果把牙膏挤爆了连着上市了M3/M4,于是Nuvia CPU上市之后从跟M2比较变成了跟M4比较,从期待中的C位变成背景板了
当年Nuvia的眼光非常超前,在2019年ARM CPU服务器市场占有率几乎为零的情况下,就是想从零开始打通这个市场,2021年被高通14亿美元收购之后,高通也给了无限的资源支持,扩招力度很大,给的薪水都是市面上最高一档的。
可惜大环境在2022年恶化的很快,加上高通的管理层战略眼光实在太差太短视,在业界ARM服务器生态都开始有起色的时候,为了股价节约开支,竟然再一次把自家的Nuvia CPU 服务器团队解散了(算上2015年已经解散过一次ARM服务器团队)
直到2025年,Nvidia的Grace ARM CPU都已经发布四年了,Vera ARM CPU都已经自研好久了,Amazon的ARM CPU Graviton都快占据CPU服务器新出货的50%了,高通才后知后觉谨慎的重启ARM服务器项目
所以这次Gerard从高通的高管位置把之前的创始团队拉出来自己干,可能是因为高通高层战略眼光实在太差屡屡错过机会,上次Nuvia想做ARM服务器,高通的承诺也因为大环境恶化没做数,结果被收购之后被高通取消了项目直接改做了laptop芯片和手机芯片
加上高通今年在手机销量上因为内存和存储历史级的巨额涨价,可以预见要受到重创(市场萎缩30%),能拿出的扩张预算有限,在高通能拿到的资源是受到掣肘的
而在创业公司里比在 Qualcomm 这种大平台里更容易拿到足够快的决策速度、团队纯度、产品定义权和资本叙事,于是选择在窗口已经被验证时重新集结老班底
但更可能因为,AI时代的CPU前景想象力真的太广阔了,完全值得重新投入一次,不是Gerard变了,而是外部市场变了
------------------------
进入2025年之后,AI agent的出现,隐隐让CPU重新变成了瓶颈
CPU服务器重新步入增长轨道,而且潜力巨大,有好几个因素:
1. 随着推理时代的到来,GPU演化到针对推理的系统级新架构,CPU 是永远在忙的总指挥orchestrator, 因为要追求token throughput,所以异构计算阶段变多 + 批处理数量batch越来越大,scheduling/routing/data flow复杂度变高,对orchestration要求也变高
所以在系统级异构推理架构里,AI加速器和GPU在CPU:GPU的配比上,也变得更为激进,从以前的1:4到Grace Blackwell的1:2,以后是很有希望达到1:1的比例的。Google TPU配Axion,Amazon Tranium配Graviton,Nvidia Rubin配自家Vera CPU
这条在我的去年11月半导体年终回顾写过,基本上在2026年成为了共识,虽然这部分主要是各家AI 芯片自研,并不是纯粹的CPU服务器,其实不算是外部CPU服务器的机会
2. 也是同一篇年终回顾里写到的:
从CPU视角去看agentic workload,routing和工具处理都在CPU上,如果把常用的agentic框架做profiling,比如SWE-Agent, LangChain, Toolformer,CPU最长可以占到90%的E2E端到端延迟,throughput瓶颈也更多的卡在CPU,CPU甚至能耗也超过了总能耗的40%
Agentic AI目前是一个CPU瓶颈更多的事情,Agent管理很多个CPU,再加上agent经常要开sandbox,很可能会成就CPU需求的新一波回暖
现在回看去年写的这个逻辑,潜力是非常大的。但其实年初可能并没有很大规模发生,年初的CPU增长和各家渲染的CPU短缺潮和这个逻辑暂时关系不大,更多可能是前几年的capex投入GPU的比例太大,造成传统CPU服务器投入不够,所以需求上升是一个回补之前传统服务器投入不够的部分。
但到了下半年甚至2027,agent会开始更广泛的铺开,比如智能导购和客服,已经占到了Amazon去年年底100万CPU采购的相当部分比例,这部分的增长是很快的
前两个逻辑,基本上是今年主流叙事在讲CPU潜力的共识,但是我的感悟是,还有另外两个逻辑被低估了:
3. 造成CPU服务器潜力更大,更长线的主逻辑,可能和agent本身没有直接关系,而是code agent带来的副产物:
coding门槛和速度的大幅优化,让“构建软件 + 连接软件 + 调用软件 + 自动化软件”这整件事便宜了一个数量级,Jevons 悖论在software供给端的展开,最终把世界推向更高的软件密度和 API 密度,这直接带来了CPU传统workload的线性上升
从2025年年底开始,coding agent迎来了质变,Claude code迎来了爆发式增长,三个月的token营收增长了三倍,那么导致的下一步必然是Code量的十倍增长,以及App数量的巨量增长
即便是在大厂,每天1m token消耗只能算是个平均水平,人均coding量必然是翻倍的(小厂就是翻十倍了),code供给量暴增,不会只停留在 repo 里,而会逐步变成更多长期运行的软件资产,长期存活的feature变多,product变多,microservice变多,API变多
长线来看,App/API所有的生产成本和生产周期会变成原来的10%,API实现极大富足。那么API的Usage就会大量的上升,这就会造成传统CPU Workload或者说CPU Seconds大量的上升,这甚至和agentic没有直接关系
时间维度上,这个逻辑并不是短期性质,Claude code的爆炸是这几个月刚发生的事情,那么产品上线,microservice,api上线,可能都要向后延迟。当软件变便宜,社会不会少用软件,只会把更多事情软件化
所以也许到下半年甚至更久才会看到,传统cpu云的需求又莫名其妙增加了,表面上看,甚至和AI agent没有直接关系
4. CPU是一个技术上很难通缩的东西,不像内存/存储有很多压缩算法会降低单任务对存储的用量,CPU workload增长转化成硬件需求增长是实打实的
比如说kvcache其实每年都有各种压缩技术出现,老的压缩技术比如kvcache的multi-head它会share一个head(GQV),这个大概会相当于4倍的压缩,再比如说去年turboquant这个技术也会新带来几倍的压缩。然后加上数据精度从FP16到现在的下一步要到FP4,精度的下降都会带来kvcache的压缩,从而带来存储方面的技术通缩。
但CPU是一个技术层面上通缩量很小的事情,目前任何的agentic的cpu workload(CPU seconds)增长都是硬件需求增长,它通缩的方面只有每年每一代跑分提高的10%到15%。如果说另外通缩因素,比如云的五倍六倍的超卖会不会影响?不会,因为它一直是超卖的,所以说超卖/利用率低这个CPU技术通缩的因素不会继续扩大了,每个增长的CPU seconds都是不怎么带打折的硬件线性增长
ARM的指引是CPU的供需缺口可能会到30%以上,这几个原因的叠加,加上AI服务器对CPU服务器产能和订单的挤压,可能会让缺口更大,各个hyperscaler的反应可能是会滞后的
------------------
CPU整体需求潜力增长的同时,ARM服务器CPU也赶上了历史上最好的时代:
Hyperscaler为了节省成本,接近50%的新增传统server CPU都是ARM,Google的Axion,Amazon的Graviton,Microsoft的Cobolt,Graviton甚至2026年的产能已经全部卖完,瓶颈成了产能
Google TPU配Axion,Amazon Tranium配Graviton,Nvidia Rubin配自家Vera CPU,这部分CPU为什么会集体转向ARM,除了成本因素之外,也因为推理系统为了追求token throughput,batch越来越高越做越复杂,自研ARM CPU以及系统性软件硬件的co-design会更方便,比如Nvidia是Dynamo去控制Vera和Rubin之间的协同
Nuvacore的规划上来看,不仅仅满足于做IP,也要做成品,因为在招聘网站上出现了validation engineer的职位
但是这次Nuvacore面临的挑战也不小:起步太晚了,无论是市场上,还是技术上,竞争都激烈了很多。CPU服务器和七年前比,已经复杂了很多,已经不再是单片CPU的竞争,而是rack系统级别的复杂度
现在开始做2028~2029年上市的CPU,要做到rack级别有竞争力,规模要大很多,基本上要几十个chiplet,500+个core拼起来,还要考虑如何适配AI agentic workload,工作量比以前明显要大的多,对一个startup的挑战比七年前也大得多
----------------
上次Nuvia在成立两年之后成功的以14亿美元出售,这次市场热度比五年前高了一个数量级,Nuvacore之后的路会怎么走呢?
如果是被收购路线,其实买家可能比五年前比并没有更多,这五年里,Google有了Axion,微软有了Cobalt,Amazon有了Graviton,Nvidia自研的Vera CPU已经成型,连ARM也打破了35年来只做IP的常规,开始做自己的AGI CPU芯片
最有可能的是Softbank系,softbank已经在ARM CPU服务器生态上布局深耕了多年,65亿美元收购了Ampere,再收购Nuvacore是很正常的事情,这个市场想象力足够大
其他的选择也可能是Meta,因为几家互联网公司里,只有Meta的silicon house没有稳定可靠的CPU服务器,有限的资源在MTIA都做AI加速器去了
但是Meta的问题在于稳定性极低,决策每个月都在变化,注意力非常短期化,项目随时取消,对Nuvacore来说完全无法兑现潜力,是一个非常糟糕的买家
但总体来说,Nuvacore的选择肯定比五年前宽了太多了,对ARM CPU服务器的潜力大家的共识都很明确,融资的难度要小很多,自己运营扩张起来,阻力比以前小很多,合作伙伴的配合程度上也因为未来预期,会容易很多
完全可以自己做大到比Nuvia当年更大的规模再考虑出路,根本不着急卖
顯示更多



