

阑夕
@foxshuo
说什么是你的自由,做什么是我的权利,如果我做的得不到你的赞同,那就对了,否则我将与你一样平淡无奇。
787 Following 172.2K Followers
看到ChatGPT新调整路由模式又引起一波抗议热浪之后,我是真有点信AI是下一个操作系统这句话了,Android、Windows的拒绝升级党以前也总是让开发商非常头疼。
Show more
0
0
0
0
0



没啥新东西,徐高7月的建策,但他本身一直不怎么受体制待见,或者说整个北大国发院那一脉现在都没啥市场,拿他们的牢骚当信号没有意义。

1/2 China's top economists have turned to Ray Dalio and Modern Monetary Theory in search of intellectual support for their arguments over debt-fuelled fiscal spending.

0
0
1
0
0
就目前来说,我对各家AI公司的深度研究功能都还挺满意的,至少能够解决我在涉猎信息时效率不足的问题,同时满足兴趣延伸的需求。
举个真实的例子,昨天在Reddit问答版刷到一个贴子「有哪些东西在十年前快死绝了却又奇迹般的重新复苏了」,其中最高赞的一个回答是:美国的独立书店。
这很让我困惑,因为这个回答太反直觉了,在我的认知框架里,受到电商的冲击,实体书店必然是一年比一年不景气,亚马逊本身也是卖书起家的,出版业一直在喊受不了平台挤压,所以为什么那个答案得到了普遍的认同?
以前为了解决这种疑问,我都需要付出大量的搜索行为,在一个个的链接里提取信息,拼凑出一个可以自圆其说的解释,整个寻找过程因为必须人工排除无效内容——差不多会占到摄取总量的70%以上——所以效率很低。
用熟AI的深度研究功能之后,过程从「先海读再挑选」变成了「先收敛再发散」,最繁琐的搜集和裁剪工作都由AI去完成,在它给我一份报告之后,我在针对具体的素材去做查证和深究。
整体时间并没有减少——所以我一直强调的是提升效率,而不是节省时间——但在新的时间分配里,大头从排查内容变成了消费内容,质量提升很明显,有种「把好钢花在刀刃上」的舒适感。
而且我一般会把需求同时发给多个支持深度研究的AI,比如「美国独立书店是怎么复兴的」这个疑惑,我就都发给了ChatGPT、豆包、Kimi、夸克等常用产品,把浏览器切到后台等它们哼哧哼哧的去出报告,去打几把游戏或者看点儿别的,等到结果出来再来交叉对比。
当然,关于促成美国独立书店回暖的原因,我也想多说几句,在电商赚得盆满钵满的时代,给实体商业留口汤喝,是真的很重要。
几家模型都提到了「Buy Local」(本地消费)文化日渐兴起的作用,这个口号的意思是,和你在电商平台花100美元相比,你在本地社区的店铺里花100美元,能有更大的比例让这笔消费在你身边循环,激活整个邻里经济,最终你也必将从中获益。
这个理论可能不太严谨,但和那种空洞的道德勒索比起来,用切身利益来打动大众的说服性明显强多了,围绕「Buy Loca」这个主张,从出版到分销再到经营的一长串产业链都起了变化。
比如出现了Bookshop和IndieCommerce这样的网站提供比亚马逊更低的交易费用,而且支持用户指定所在地的任何一家书店发货,书店不需要自建电商系统或是找人来直播带货,只需要把库存接进去就能拿到订单。
再就是书店品牌方开始下放权力,把门店选品交给店员负责,有点主理人的意思,比如以前在最好的展示位推荐什么书,要么是出版商出钱买位置,要么是放主流畅销书,但是最近普遍都由门店自行决定,比如基于「BookTok」——TikTok上的热门标签,反映网红们都在读什么书——来做店内布置。
反不合理的分配制度,而不是反互联网本身,这点很聪明,不仅避免了一刀切的草率,甚至还反过来影响了那些规模更大的连锁书店,在全国拥有几百家门店的巴诺书店就明确提出要让每一家店都变得更像独立书店,给经理更多的决定权。
还有策展活动的兴盛,坚持把读书会、作者讲座、开放麦之夜组织下去,把到书店打卡这件事情塑造成电商购买无法得到的氛围感,喜欢读书的人一般都在网上不太合群,所以很愿意走进书店感受「同温层」。
在多项因素的共同作用下,美国独立书店的生存数量在2009年陷入谷底之后逐渐反弹,10年内增长了50%,即使经历了疫情有所放缓,但很快就重回净增长,带着纸质书走出衰退,书店销售额连续跑赢大盘,越过健康线。
之前我在说AI并没有降低我用搜索的频率,也是因为这种增强兴趣的用法其实会激发很多新的回流行为,比如针对结果里的一些细节直接划线进行二次搜索这样,原则一直如此,AI可以用来省力气,但大可不必省脑子,要和AI一起学习,而不是让AI替你学习。
最后说一下提示词,我用的是最经典的三段式结构,锁定人设、交待背景、细化要求,泛用性很高,可以按需修改:
**目标设定:你是商业财经领域的专家,擅长挖掘和分析数据,并做出深入浅出的总结,你在和聪明人对话,所以必须极其认真的重视任务,提供最专业的解答。
**思考模式:任何问题都需要遵循层层递进、逐步拆解的思考方式,避免草率作出结论,同时需要考虑不同的观点、原理和逻辑,确保回答的高质量,在特定的复杂概念上,可以选择性采用费曼的语言技巧,化繁为简,确保表达自然、真实和有深度。
**任务说明:你需要解决的课题是「美国独立书店的复兴」,这个疑问来自我在Reddit看到的一个广受认同的观点,认为美国的独立书店在过去十年里重新有了活力,希望你能帮我验证这个说法,并给出详细的分析报告,并对趋势做出全面的梳理和总结,尽可能的检索全网信息,但要注意数据的准确性,任何有待核实的问题都要给出备注,
**输出格式:输出Markdown格式的研究报告,层次分明,重点清晰,必要时制作表格,总体不低于8000字。
Show more
0
0
8
178
23
GPT-5发布之后,「纽约客」刊出一篇长文评论,充满了这本杂志特有的那种讽刺味儿,就差没把「眼见他起高楼,眼见他宴宾客,眼见他楼塌了」写到脸上了,我手搓翻译了全文,作为睡前读物给你们感受一下。
如果AI不能继续变聪明了,我们该怎么办 - by Cal Newport
所有和AI相关的兴奋和焦虑,源头都能追溯到2020年的1月。
当时,OpenAI的研究团队发布了一份30页的技术报告,题为「神经语言模型的扩展规律」(Scaling Laws for Neural Language Models),撰写者包括后来创办了Anthropic的Dario Amodei,他们试图摸清一个生僻却重要的问题:如果持续增强语言模型的训练规模,它的性能会发生怎样的变化?
那会儿绝大多数机器学习的专家都认为,语言模型达到一定规模后就会开始背题,从而在实际交互中变得不太可用。
但是OpenAI的这篇论文提出了截然相反的判断:语言模型越大,智力就会越高,甚至可以说,这种进化可能遵循类似「冥率分布」的法则,呈现出一条类似曲棍球棒的上升曲线。
换句话说,只要不断构建更大规模的语言模型,并用更大的数据集进行训练,那么模型就会一直变强下去。几个月后,OpenAI发布了GPT-3,它的规模是GPT-2的十倍,性能也大幅提高,似乎验证了「扩展定律」(Scaling Laws)的存在。
一夜之间,那种曾被视为遥不可及的通用人工智能(AGI)——在各项任务里都能表现得和人类一样好——似乎近在咫尺了,如果「扩展定律」成立,AI公司只要向语言模型不断投入资金和算力就能实现通用人工智能。
随后一年里,Sam Altman发布了一篇题为「万物摩尔定律」的博客文章,认为AI将接管人类从事的一般向工作,并为持有资本的人创造难以想象的财富。
他是这么写的:「这场技术革命不可阻挡。世界将发生剧烈变化,我们也必须进行同样剧烈的政策调整,才能公平分配这些财富,并让更多人过上他们想要的生活。」
「扩展定律」必将通向通用人工智能,这成了AI界的信仰。2022年,纽约大学心理与神经科学教授Gary Marcus对OpenAI的那篇论文提出批评,认为「扩展定律」只是一个观察的结果,而非引力这种客观规律。
这下子Gary Marcus捅了马蜂窝,据他所说,自己从来没有因为写了一篇文章而被那么多声名显赫的大佬嘲笑过,从Sam Altman、Greg Brockman到Yann LeCun、Elon Musk,这种待遇实际上把他从机器学习这个圈子里驱逐了出去。
后来发生的故事大家都很熟悉了,ChatGPT成为了史上用户增长最快的产品,2023年3月,GPT-4的发布让AI性能的提高变得匪夷所思,以致于微软专门为此新写了一篇论文,标题是梦幻般的「通用人工智能的火花」,在接下来的一年里,涌入AI行业的风险投资增加了8成。
然而,进展的放缓同样来得猝不及防。GPT-4后的2年多时间里,OpenAI没有发布跨代际的模型,改为专注于一些专业化的版本更新,让普通人难以跟进,业内也开始有声音质疑「扩展定律」的失效。
OpenAI的联合创始人Ilya Sutskever去年曾对路透社表示:「2010年代是扩展的年代,现在我们又回到了探索与发现的年代,大家都在寻找下一个突破点。」
同时期在TechCrunch发布的一篇报道也透露了这种变得普遍起来的情绪:「如今大家好像又承认了,单靠更多的算力和数据来训练模型不能造出一个全知全能的赛博之神。」
不过,这些声音很多时候还是会被那些更为惊人的头条新闻淹没掉,像是Dario Amodei认为「AI几乎已经在所有的智力型任务上超过人类,未来五年内至少会有一半的初级文职工作会被代替」,而Sam Altman和Mark Zuckerberg都在今年夏天宣称距离开发出「超级智能」只差临门一脚。
就在上周,OpenAI终于发布了GPT-5,所有人都期待它能带来AI能力的又一次重大飞跃。在早期评测中,一些表选确实可圈可点。
比如科技博主Mrwhosetheboss要求GPT-5创建一款以宝可梦作为棋子的国际象棋之后,得到的结果很明显比GPT-4 mini-high要好,他还发现 GPT-5能为他的YouTube频道写出比GPT-4o更优秀的脚本,但他也意识到,GPT-4o依然能在生成图片的技能上打败GPT-5,而且GPT-5也不是完全没有幻觉。
几小时内,Reddit的r/ChatGPT版块里就充满了失望的氛围,一个贴子把GPT-5称作「史上最垃圾的付费产品」,在一次AMA问答里,前来做客的Sam Altman和OpenAI的其他工程师全程处于挨批的位置,不得不回应各种尖锐之辞。
Gary Marcus终于舒服了,他给GPT-5的发布会盖棺定论:姗姗来迟、炒作过度、失望透顶。
GPT-5的问世让人们很难再去相信AI界的夸张预测,反而让Gary Marcus这样的批评者变得温和起来。他们认为AI固然重要,但不会很快改变我们现有的生活,大家应该接受现实,那就是AI在短期内不可能变得更好了。
OpenAI不是故意等了将近2年半的时间才发布GPT-5的,根据The Information的报道,去年春天,Sam Altman就告诉员工下一代模型——代号「猎户座」——将明显优于GPT-4。然而,到了秋天,事情就变得不那么乐观了:「尽管新模型的表现的确超过了前代,但相比GPT-3到GPT-4的飞跃,这次的提升幅度要小得多。」
「猎户座」的失利加剧了那种日益蔓延的怀疑:「扩展定律」并非真的定律。如果构建越来越大的模型所产生的回报开始递减,AI公司就需要新的策略来训练它们的模型产品。
很快的,AI公司将目光转向了「后训练」(Post-Training Improvements)。语言模型通常先要经过「预训练」,也就是通过吸收整个互联网的信息来增强智能。但也可以在此之后继续优化,帮助模型更好的利用已经学会的知识,这就是「后训练」,也被称作强化学习,用来指导模型在特定类型的任务上表现更好,或者教会模型在遇到困难时懂得消耗更多Tokens进行解题。
这就好比是造车:「预训练」相当于把车生产出来,「后训练」则是对车辆进行改装。OpenAI的那篇论文提到过,「预训练」越多,造出来的车就越优秀,如果GPT-3是轿车,GPT-4就是跑车。但当这种进步受阻后,行业里的工作重点就切换到让已有车辆的性能变得更好,科学家也开始做起了技师的活儿。
科技巨头们也迅速的圆润起来,开始对「后训练」寄予厚望,微软的掌门Satya Nadella去年表示大家正在看到一个新的「扩展定律」冉冉升起,投资者Anjney Midha也表示「扩展定律」的第二条命启动了。
很快,OpenAI于去年年底发布了o1,通过「后训练」为模型赋予了推理和编程能力,随即又连续发布了o3-mini、o3-mini-high、o4-mini、o4-mini-high 和 o3-pro,每个模型都采用了量身定制的「后训练」组合。
同行也都在做出类似的转身。Anthropic在今年2月发布的Claude 3.7 Sonnet里尝试了「后训练」改进方法,并将其作为Claude 4系列模型的核心。
Elon Musk的xAI在Grok 3之前仍在追求「扩展定律」,其在训练时消耗了惊人的10万块H100芯片——这比GPT-4高出好几倍——但当Grok 3依然没能显著超过竞争对手后,xAI也选择了「后训练」来开发Grok 4。
GPT-5可以说是这种发展轨迹的延续,它更像是对一系列「后训练」产品的整合,而不是一款脱胎换骨的全新模型。
那么问题来了,新的方法能否让我们重返AGI之路?OpenAI在GPT-5的发布中展示了几十张图表,用于量化模型在多语种编程、多模态推理等领域的进步,这没毛病,但我们都还记得,GPT-4的发布时可不需要这么多的图表,每个人使用几分钟后就能感受到它是多么不可思议的创造。
部分基准测试本身也值得怀疑。自从o1问世,AI公司就在宣传推理模型的意义。但在今年6月,苹果发布了一篇论文「思维的错觉」(The Illusion of Thinking),发现所谓先进的推理模型在任务复杂度超过一定阈值后,便会产生性能崩溃的现象,从o3-mini、到Claude 3.7 Sonnet以及DeepSeek-R1,无一幸免。
上周,亚利桑那州立大学的研究团队得出了一个更直白的结论:推理能力是一种假象,一旦出题超过训练范围就会迫使模型宕机,而且在测试题库里拿到高分,和真正解决现实问题之间,存在着巨大的鸿沟。
Gary Marcus还在幸灾乐祸:「我没听到哪家公司会说2025年的模型比2024年的模型更好用,测试的分数可不能拿来提高工作效率。」是的,把你的凯美瑞开进改装店可以带来很大的性能提升,但再怎么改,它也变不成法拉利。
我让包括Gary Marcus在内的几个怀疑论者预测AI在未来几年能对经济产生多大的影响,其中一个科技分析师Ed Zitro断言AI只是一个500亿美金的市场,而非万亿级别,Gary Marcus说得更刺耳,「好的话是500亿,不好的话也就100亿。」
语言学教授Emily Bender则说,「市场的大小取决于有多少管理层会被这项技术蒙蔽双眼,并改造工作岗位,这样的情况越普遍,普通人的处境也就越糟糕。」
他们的观点过去常被当作是「落伍的老头儿老太太们对着天上的云朵哈气」——这来自一条真实的推文评论——公众更加愿意倾听科技公司的宏大愿景。或许,这种局面正在扭转。
如果他们对于AI的悲观预测是对的,那么未来会以渐进而非突变的方式降临,很多人会用AI来查询信息、撰写报告,编程和学术等领域可能会走得稍微快一点,少数职业——比如配音、文案——基本消失,但AI未必会彻底扰乱整个就业市场,而「超级智能」这样的夸张概念也不会再有太大的信徒市场。
继续买单AI这件事情或许也有危险。目前,美股总市值里大概有35%都集中在7巨头身上,这关联到很多人的养老金,而7巨头在过去18个月里总计往AI砸进了5600亿美金的资本支出,而收入却只有350亿,这太疯狂了。
不过,即使是温和派,也在提醒人类不要就此过于轻视AI。Gary Marcus讨厌语言模型,但他也相信,通过别的技术路线,通用人工智能还是有机会在2030年实现。趁着这段喘息期,人类应当提前做好准备,制定有效的监管措施,想清楚伦理问题。
对了,在OpenAI那篇关于「扩展定律」的论文附录里,有一个「注意事项」的篇章,后来的报道往往忽略了此处。作者写道:「目前我们并没有得出完善的理论体系,模型规模和算力供给之间的扩展关系非常神秘。」事实证明,「扩展定律」有时有效,有时无效,终究不是铁律,而教会机器学会思考这一事业,仍然充满谜团。
我们是该少一些傲慢,多一些谨慎。
Show more
0
0
9
144
29
听不明白播客采访还不上网贷的年轻人,一个比一个难绷。
第一个嘉宾最高也就欠了5-6万的贷款,年入水平差不多在10万左右,怎么看都不像是还不上的样子,结果听他说为了省钱把个人开支压到极限的其中一条是「每顿饭的开销不超过30元」……大哥你是真没穷过啊。
第二个嘉宾更离谱了,已婚无娃,有房无贷,十年前两口子年入50万+,自认为是突破阶级固化的样本,结果靠自己的努力把钱全还回去了,创业+炒币,老婆赚钱的速度赶不上自己亏钱的速度,现在欠了160万。
🙃
Show more
0
0
0
2
0
QuestMobile的2025AI半年报出来了,国内的AI产业从统计数据来看不太理想:
- 移动端和PC端两大场景AI产品的活跃用户规模双双下滑,分别少了2000万和3000万,原生App的大盘增长完全停掉了,相比之下,隔壁ChatGPT已经7亿周活,还忙着出防沉迷模式;
- 为了挽尊,QuestMobile发明了一个还有增长的插件市场,比如在百度搜索时用到了AI摘要就算一个活跃,这种功能化的场景,还有5000万的增量用户;
- 11亿网民,PC端的AI用户顶天也就1.8亿,这太萎靡了,这意味着基于Web的产品创新完全没有回报,只有出海一条路可走,最后大概率要在避险策略下迁址新加坡;
- Kimi、文小言、纳米、星野、智谱清言、讯飞星火都上榜了用户流失的重灾区,猫箱更是跌了55%,陪伴产品的留存不忍直视;
- DeepSeek的流失用户里,超过一半去了百度,AI搜索目前还是被验证的最主流需求,QQ浏览器和夸克也都是接盘DeepSeek的剩余赢家;
- 夸克的月活用户平均每月打开65次,断层领先,是百度的6倍以上,微博智搜排在第2,表现同样突出;
- 6月全网Token消耗量116.3万亿,差不多是去年公有云全年的量级,涨得很快,也符合预期,不过对比的话,光是Google一家今年6月就消耗了980万亿Token,口径或有差别,参考即可;
- 在过亿月活级别的AI应用里,豆包是唯一一个还能有2位数增长的,11.4%的复合增长率,足够吊打所有竞品。
Show more
0
0
0
2
0




一个美国工程师在Reddit分享了他在台积电亚利桑那工厂干了4年后的体验,全是吐槽哈哈哈:
* 这座工厂是美国重振制造业的推动结果,享受了不少补贴,我之前也翻译过文章,讲述在这座工厂里产生的文化矛盾。
简单介绍一下背景,我是在2021年拿到offer的,当年夏天就去了台湾培训,是最早从美国派去的一批人。我不想说太多细节,但那真是一场彻底的灾难,他们多次更改航班日期,发给我们的笔记本电脑根本不能用,关于宿舍的大小也撒了谎……总之,我把这些当成疫情期间的特殊情况,算了。
然后我们到了台南,依然很是糟糕,他们没有做好培训计划,几乎没有会说英语的人,对我们这批新员工,他们根本不怎么搭理,私下里说「美国人工资太高,我们不配教他们。」
经过几年在台湾的「培训」,20%的人因为工作条件的恶劣而选择辞职,而我们这些忍受下来的人终于回到了亚利桑那州。显然,一个新的晶圆厂肯定会出问题,但台积电永远会让所有问题变得更加严重。
施工进度落后,因为他们根本没有任何计划。因为觉得亚利桑那州的工人能力不足,他们总会从台湾派人过来收拾残局,甚至让我们进入没有许可资格的设施工作,将我们暴露在不合规的危险环境中,而当我们为了安全表示拒绝后,他们则以年底会在绩效上打差评来做回应。
在经历了这一切之后,我想,好吧,那只是其他地区的公司来美国建厂时必然遭遇的阵痛,一定会有好转的,对吧……错了,情况变得越来越糟。和我同期入职的员工大约有70%都跑路了,所以我们必须不断的培训新员工,而且,我后来联系过一些离职员工,他们都告诉我,换了公司之后明显改善了自己的处境。
在台积电亚利桑那工厂,所有的项目都来自台湾的「母厂」,无论如何都要遵守,完全不考虑逻辑或理由。因此,不存在任何的创新空间,更不需要员工思考什么,工作就是每天按时到岗,然后被告知今天要做什么,计划不断变更,修正,严重落后,最后反复循环。
我曾参与过所在项目组的实习生/新员工面试(我猜是因为英语是我的第一语言),而面试前他们给我准备的「指导意见」非常恶心。
我被要求优先考虑来自台湾地区的求职者,其次就是持有签证的人,因为「这些人更容易被控制」,他们不想雇佣没有移民限制的美国人,因为他们一言不合就会辞职,所以「绿卡」才是迫使员工长久工作下去的胡萝卜。我还被告知不要雇佣印度人,他们鄙夷的称呼印度求职者为「PhD People」。
我面试过两名最后拿到offer的求职者,我的老板后来对我说,这两个人在面试前就确定要进来了,他们有内部关系,面试只是走个形式,我tm……我理解「关系重于能力」的潜规则,但裙带现象如此严重,还是超出了我的想象。
我还被告知在面试里要打足预防针,强调「台湾式的工作文化」,换句话说,就是你每天都会挨骂,还得完成不可能的截止期限,因为你的同事随时都会变少,流失率太高了。
每天上班也是一场噩梦,他们期望你把全部的生命都奉献给工作。我的岗位是年薪制,然而不管工作多长时间,薪水都是一样的,哪怕经常要加班到晚上9点,我还有一些同事日均工作14-16个小时……这甚至都算正常的。
如果不忙的话,大多数人会在晚上8点左右下班,然而管理层会故意在下午4-5点布置「紧急」且「明天早上就要讨论」的任务,这意味着我们必须加班完成。
工作文化本身也很让人心累,台湾地区来的人有50%的收入来自奖金,这个奖金除了受到绩效影响,更让工作变得像是一场人际关系的比赛,更重要的是看你犯错多少。所以,如果你处在一个一半以上的收入取决于不能犯错的环境里,你的首选态度必然是回避任何多余的事情,对吧?
这正是大多数人的选择。所以,如果在工作时你想求助于同事,他们要么视而不见,要么把你推给别人,因为如果介入了你的工作,他们就得承担新的责任。这造成了一种非常冷漠的风气,没有团队合作,没有相互帮助,于是效率变得更加惨不忍睹。
台湾人很重视台积电,认为加入这家公司是这辈子的荣耀,我很尊重这一点,但我不是台湾人,我乐意把工作做好,学习新东西,但我不会把命卖给公司,而大多数台湾地区的员工会。他们把工作视为生活中第一且唯一的事情,家庭是次要的,我无法理解,我是为了生活而工作,为什么他们能够为了工作而生活?
台湾人似乎很喜欢歧视别人,我听到过他们嘲笑别人的口音、外貌和残疾,他们通常会用中文这么交流,但因为我在培训期间学了不少中文,所以能听懂他们在说什么。工作场合像是高中那样,每个人都有自己的八卦圈子,因为没有外部生活,内部员工之间的恋爱很常见。
我在台湾培训时,有个新入职的女孩,面试她的经理把她的Facebook照片发到群里,让大家打分。她被录用后,因为体重的增加,看上去和照片上的不太一样,有一个男员工对她喊道「哇,我没想到你这么胖」,然后跑到一边和朋友们一起笑,她在那哭了一整天,然后请了两天假……你很难想象这是成年人会做的事情。
你们可能会问,那么在台积电工作的好处是什么?我相信大多数员工都会说两个优点,而我则对这两个优点持有保留意见。
1、他们不裁员。这是真的,我从来没见过有人被裁。实际上在台积电被开除几乎是不可能的——除非造成了非常严重的事故——所以你可能觉得这很友好,工作有保障,可以一辈子干下去。虽然确实不用担心被裁,但这也导致了一个质量很低的员工群体。想象一下,你在一个保留了所有最差员工的地方工作,优秀的人会被提拔出这个团队,而最差的那群人却抱在了一起。所以你进入这样的团队之后,就不得不额外努力来弥补他们的不足。但如果你找到了一个不错的团队并能忍受下去,那么恭喜你,你确实得到了一个铁饭碗。我的老板在工作期间说过这么一句话:「台积电不裁员,有需要时,他们只会逼你辞职。」
2、薪资。是的,台积电的薪水的确很高。他们会故意开一个市场价略高的待遇来吸引你,但工作几年之后,你会发现涨薪速度低于行业,很快就会低于市场。不过这可能是工程师这个职业的普遍问题,跳槽永远是涨薪的最好办法。举个例子,今年我离职后,新工作涨了30%的薪水。所以你要知道,当下的工资看起来不错,不意味着它会一直不错。另外,台积电的薪资高是有原因的,他们期望你付出更多。这是一个与魔鬼交易的局面,如果你比竞争对手多拿10%的薪水,但工作量多了50%,那么扪心自问,你真的赚得更多吗?
我想给其他对台积电的工作有兴趣的人一个建议:我觉得他们的实习项目相对很好,有助于丰富简历,薪水可观,而且有明确的结束时间,这是最好的部分,他们确实会故意对实习生很好,不给实习生太大的压力(这是我带实习生时来自老板的直接指示)。
所以你们要知道,如果决定成为全职员工,压力和工作量会大幅增加,眼前的求职市场不太景气,如果你刚毕业、急需一份工作的话,台积电可以是一个不错的起点,尤其对于那些单身、没有家庭和其他责任的年轻人来说,你们可以赚到不错的收入,积累一些经验,然后再换工作。
如果你已经有丰富的就业经验了,那么我建议你还是避开台积电,因为你来了就会觉得是在坐牢——不能用手机、全天被监控、开会时被当成小孩,等等——另外,如果你申请时看到类似「我们正在扩张招聘」这样的字眼,其实非常具有误导性。他们确实一直在扩张和建造更多的晶圆厂,但大约90%的职位空缺,实际上是因为有人离职了,而员工流动率非常高。
作为最后的说明,这只是我的个人经历,所以像互联网上的所有信息一样,请带着怀疑的态度看待。我相信确实有人喜欢在那里工作(我从没遇到过,但他们肯定存在,对吧?),并且没有我经历的那些问题。那里并非全是糟糕和可怕,只是我觉得那不是一个能促进我职业发展或心理健康的地方,所以我选择离开了。
Show more
0
0
5
34
7

赛道的差别:同样是靠批条子的权力套现,饿了么CEO花了2年时间哼哧哼哧的贪了4000万,因为一时半会洗不白还智能以现金的形式打包存放在出租屋里,隔壁快手中层员工1年就贪了1.4个亿,而且直接兑成了比特币…… https://t.co/xU4sfOP6M4
Show more


0
0
0
0
0
昨天Coze的两款核心产品被开源到GitHub了,分别是Agent的开发平台Coze Studio和管理平台Coze Loop,迎来了开发者阵营的一片好评。
今年是Agent大年,Coze也是起了个大早的标杆,但是因为主要价值在于服务专业用户搭建工作流,Coze和后面的那一拨AI Agent反倒没有走进同一条河流,于是各有各的热闹。
我自己对Coze「搭积木」的玩法还挺喜欢的,比起全托管的Agent,这种半托换的控制力更好,不会出现AI干AI的、我急我的这种矛盾。
比如你们可能记得,前段时间我发了百度的市值被大家用来听歌的腾讯音乐给超了的截图,那个其实就是更早时候在群里看到两家公司市值接近的话题,但当时还有一点差距。
我觉得这是很戏剧性的时刻,但自己肯定没时间每天都去盯着两家公司的股价然后等到市值交错的瞬间赶紧截图,这也太蠢了,当时就是去Coze搭了一个非常简单的智能体,让它每天在美股收盘时去查询百度和腾讯音乐的市值,并对比做出判断,一旦发现百度的市值低于腾讯音乐,就给我发一条消息。
之后我就扔着没管了,直到一天起床后收到提醒,马上就知道节目效果终于出现了,所以对我来说,这样可持续工作的智能体,和我在通用Agent里需要的一次性代码服务,是不一样的,很多Agent产品,我用得频繁,换得也频繁,但Coze我虽然用得不多,每次遇到事儿却是真会「复购」。
这次开源的Coze Studio,就是Coze的核心开发模块,明确意义上的六边形战士,应用接口非常丰富,可以很爽的调用第三方工具,另一个Coze Loop就跟我这样的非商业用户关系不大了,是为智能体的产品化提供支持的。
比较值得点出来的是,Coze开源选择了Apache 2.0开源协议,这是对商业化最友好的开源协议,没有之一,几乎不会对使用者做出任何限制,一视同仁的将技术开放给从个人开发者到各种体量的公司,而且它不但授予用户版权,还明确授予了与贡献相关的专利许可,确保了商用场景的法律安全性。
多少能够理解Agent赛道的开发者们为此开香槟的态度,技术的流动加速,对于一个新兴多变的行业来说,永远都是不嫌多的,开源社区越是繁荣,AGI平等降临到每一个人手上的概率就会越高。
Show more
0
0
0
0
0
视频里明晃晃的挂着「日本」「男宝宝」,然后评论区是这样的⋯⋯我希望AI赶紧接管互联网。 https://t.co/WkSkImH1iV


0
0
0
1
0
把一版旧提示词又改了改,发现可以生成Coser的捂脸床照……😅
[名字]来自[作品],躺在床上,膝盖弯曲,遮住了脸。是一张随意用手电筒拍的照片。照片有些运动模糊,且略微过曝。角度尴尬,构图不存在,整体效果极其平庸——就像无意中从口袋掏出手机拍照时拍到的意外照片。房间昏暗。照片从上方完整地展示了床,床上不空,有毯子和毛绒玩具。除了手电筒外,还有微弱的 RGB 灯光照亮场景。光线昏暗。
远坂凛、明日香、芭芭拉、樱岛麻衣。(1/n)
Show more




0
0
2
4
0
昨天那个淘宝闪购专家纪要,不出意外的被阿里「辟谣」了,但用词很软,只说内部没有冲单计划,很形式主义的口吻。
其实看过原始PDF的应该都清楚,那个信息量是没法编出来的,更别说用AI去生成了,更直接的证据就是,我那条微博没有被投诉,阿里也没找我「沟通」⋯⋯
挺好的,相互理解。
今天来说说专家纪要这种大厂深恶痛绝的情报外流模式吧,所谓的专家,一般都是大厂中层的内鬼,能拿到一手业务数据和战略执行细节,而这些材料存在水下的市场需求,包括券商、投行、竞对、股东都想了解,于是就会有咨询公司从中撮合,按小时付费拉群开电话会,成本摊派。
至于具体价格,受到内鬼的职级权限、交流主题、客户份量等变量影响,波动很大,从最低档的每小时千把块钱,到高价值的可以冲到每小时6位数,就很浮夸,但因频次也没那么高,说赚大钱也不至于,只是内鬼赚外快的一种方法,比不上其他类型的贪腐机会,当然被发现的风险也更低。
阿里这次交流里的专家被频繁问到淘宝的打法到底和美团有什么区别,但解释得很勉强也相当不耐烦,我感觉也就是一个P8,拿不到太多敏感数据,主要是用来确认阿里对外卖的投入边界的,资本市场希望基于真实信息再去用脚投票。
一个合格的内鬼必须清楚怎么安全的把情报送出去,比如对终端数据加减5%都算基操,或者把边角料包装成核心信息,有些特别重要的数据就算知道也不能随便说,否则还是经不起查。
可以参考的一个案例,是去年快手通过内部检举制度撸掉了投资发展部的一个员工,就是因为接单太勤了,「早9晚12的躲起来开会」,618刚结束就把精确到小数点后两位数的交易数据卖给外部,让公司特别难受,所以就算她用了变声器开会,该被揪出来还是躲不掉,但她这么把副业当主页干了大半年,最后获利有多少呢,也就70多万,真的算体力活了。
另外就是,有的时候,在不影响全局规划的情况下,大厂也会适度利用专家纪要这种形式,去向市场传递一些自己作为官方不便输出的信号,这个时候的内鬼则相当于喂料的角色,反过来薅咨询公司的信用,很有意思。
Show more
0
0
6
45
6
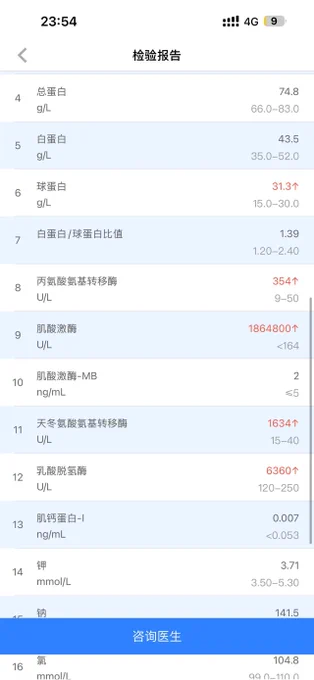
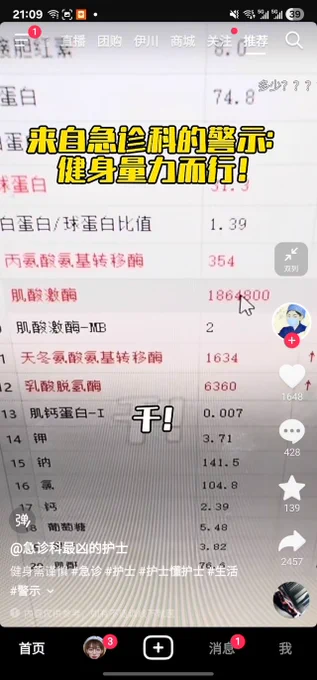
笑死,我有个群友在蔚来天天加班还要给锻炼加量,前段时间突然半夜尿血,去医院挂了急诊后直接被送进ICU了,肌酸激酶飙到了186万⋯⋯(图1)然后今天发现被当班护士当成素材发抖音了(图2)哈哈哈哈哈哈哈哈哈 https://t.co/dLjN1iIOJZ
Show more
0
0
0
0
0















