檢索結果 即美光,
即美光, 貼吧
一個關鍵字就是一個貼吧,路徑全站唯一。
用戶
未找到
包含 即美光, 的搜尋結果

著名投资人但斌的基金公司东方港湾提交了一季度持仓报告。新增三支股票:#CRCL## 即circle,#MU##即美光,# #TSM##即台积电。前三重仓仍然是谷歌、英伟达、苹果。我的关注与该持仓有重合的是:谷歌、苹果、英伟达、美光、环状网络。我还有一些关注是该持仓表里没有的:英特尔、AMD、闪迪、海力士、马匹材料等。#
顯示更多


美股美光 MU 预测
预测品种:MU $MU
预测时间: 5 月12 日
预测时价格:795.33 美金
预测周期: 丙午年及日走势预测
预测观点:
2026 年丙午年走势分析:
请教奇门遁甲美光在接下来的丙午年走势是哪一宫?奇门遁甲给予的提示是乾六宫,格局是乙加癸,天英,景门,八神螣蛇会白虎,暗干丙,临了马星。
这里奇门遁甲的格局,明确的说明宜退不宜进,是明确的退避信号,整个市场是围绕消息面和愿景来炒作的,天英,景门,虚火,来的快,猛烈,但是不够持久,短期的热度,来的快,去的快,在本月下个月午月还是有炒作的空间,围绕消息面,无论真假,来回的炒作,炒作中是暗藏杀机的,过了夏天以后,这把炒作的火过去以后,很容易之前看好的消息变成利空,对盘面形成大的抛压,且这种抛压迅速,砸盘不会拖泥带水,反应时间比较短。
到这里,我就有很强的困惑,因为我目前推特上刷到的消息面,都是非常看好美光的,那我在思考,是不是这两个月五六月,即癸巳月、甲午月美光将会继续拉升?
我请教奇门遁甲癸巳月走势,第一次奇门遁甲给予我提示坤二宫,坤二宫我保持疑惑,因为没有直接上卦,第二次请教是巽四宫,巽宫格局是戊加辛,玄武,值符,天蓬,休门,暗干癸,这里显示投机和风险顶级资金都在这里蛰伏,等待,或许是等待一个政策,或者是在等待时机,目前风险资金不敢贸然强攻,处于观望,试探的状态,盘面会短暂的进入一个表面平静的状态,在接下来癸巳月当中主力的动作是藏在水下的,这个过程伴随着小跌,但是问题不大。
巽四宫更多传递的是风险资金的一种心理状态,坤二宫是真正的承接,这就是为什么奇门遁甲第一次给予我提示坤二宫原因。
坤宫格局庚加己,天冲,伤门,九天,太阴,暗干辛,这里我的推测是主力和投机风险资金在观望了一段时间后,会快速的拉盘,突发性很强,然后拉升到一定高点以后,会暗中出货,fomo 用户掉进坑里,这种拉升不是正常的拉升,带有破坏性的拉升,容易先拉后跌,奇门遁甲给予的坤宫的信息直接提示就是百事不可为,谋为必凶。
这里很可能一种情况就是主力拉升的高度会放大到极致,集体散户、市场一片看好,情绪到顶,随后开始下跌。
6 月 甲午月美光 mu 走势如何?
奇门遁甲给予我的提示是震三宫,我没有看到上卦,第二次给予我提示的是巽四宫。巽四宫是震三宫的前因,巽四宫在公历的 6 月,主力会开始休息一段时间,测试盘面,随后会到了震三宫。
震三宫格局是癸加庚,白虎,九天,天心,开门,这个月走势波动还是比较大的,盘面争议很大,暴涨暴跌的,可能这里会有多头强行拉盘,但是多头在这个月是很不利的,天时不利,地利不利,处于拉不动的状态,只要强行拉升,就会被压下来,空头力量比较强,这个月容易呈现放量抛压的状态。
日分析
5月12 日分析
12 日为丙戌日,奇门遁甲提示在 坤二宫,这里有快速拉升回落的迹象。
13 日为丁酉日(23:00-4:00),奇门遁甲提示的是 1 宫
以上仅为依托奇门遁甲传统文化数理格局,做时空气场、市场情绪、资金行为逻辑的纯学术交流推演,不构成任何买卖操作建议、投资决策指导,投资者请依据自身专业判断及正规市场研报理性决策,自主承担投资风险。
顯示更多



如果觉得现在美股是人声鼎沸时,那么AI你也是一样的观点
就拿中国来说,中国已经进入「全民 AI 化」,但还没进入「全民会用 AI」,AI是一个长期产业周期,而现在AI 的真正大爆发,还没到来。
龙虾的普及率也没我们想象的那么高,但确实是因为开始使用龙虾后,我们才感觉token的消耗速度那么快。现实生活中,真正用龙虾的人有几个呢?
如果从目前实际应用去看中,目前消耗token最大的是「视频生成」,即梦、Seedance、可灵这些产品是消耗token的大户,《霍去病》这部AI短剧的暴富神话,让更多人进入了AI短剧行业。
AI Agent的token消耗排名第二,AI编程第三,最后是最接地气的内容生成 + 电商运营。
美光、英伟达、台积电这些涨,核心逻辑都是AI的基础设置不够用,供需关系导致的
HBM
GPU
数据中心
电力
散热
整个产业链都还在疯狂扩建。
现在 AI 用户虽然已经很多,但是大部分人停留在问问题、写文案这些低消耗场景上,真正的大量消耗token、疯狂吃断离的阶段,还没到来。
可某一天,当内存条价格开始往下走,供大于求的时候,才是我们应该警惕的。
顯示更多

Openai搞的这个Cerebras 芯片比较有意思😅
1. 晶圆级尺寸 (Wafer-Scale):世界上最大的芯片,有多大呢,脸盘那么大.😅
晶体管数量: 拥有 4 万亿个晶体管(作为对比,H100 只有 800 亿个)
2. 极高的片上内存带宽 (On-chip SRAM)
这是 Cerebras 吊打 GPU 的核心武器。
消除瓶颈: 在传统的 GPU 架构中,模型计算时需要在显存(HBM)和计算核心(Core)之间频繁搬运数据,这产生了巨大的能耗和延迟。(内存计算会稀释HBM增长率,但蛋糕足够大,同时SRAM的成本也很高,前期对三星海力士美光三巨头威胁不大)
全片上存储: Cerebras 拥有高达 44GB 的片上 SRAM 内存,带宽达到了每秒 21 PB (PetaBytes)。这意味着模型的大部分权重可以完全存储在芯片内部,读写速度比 GPU 的显存快上千倍,从而实现了 OpenAI 模型那样的“秒速”推理。
3. 极简的编程与扩展
单机即集群: 由于芯片本身足够大,一个 Cerebras 节点(CS-3)的算力就相当于几十个甚至上百个传统的 GPU 节点。
无需切分模型: 开发者不需要像在 GPU 集群上那样,把一个大模型拆分成很多份并考虑复杂的跨服务器通讯(Model Parallelism)。在 Cerebras 看来,整个模型就在“一块”芯片上跑。
4. 针对大语言模型 (LLM) 的稀疏优化
处理零值: AI 模型中有很多权重是“零”(稀疏性),传统 GPU 依然会对这些零进行无效计算。Cerebras 芯片内置了稀疏计算引擎,能够直接跳过零值,从而进一步榨取性能。
顯示更多

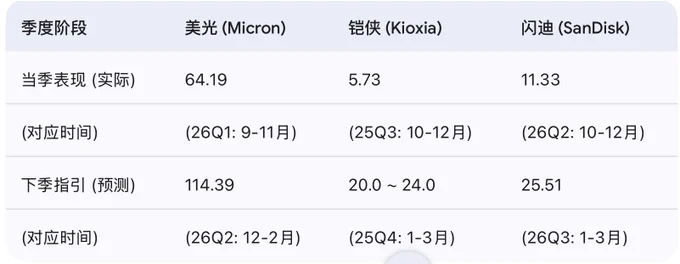
铠侠(Kioxia Holdings,代码:285A) 于2026年2月12日发布的最新季度财报(2025财年第三季度,即2025年10月至12月)。
铠侠本次财报表现极其强劲,尤其是首次公开了此前一直非开示(未公开)的全年利润预测,且数额远超市场预期。以下是为您整理的精简精准数据:
铠侠 (Kioxia) 2025财年Q3 财报核心提炼
报告期: 2025年10月1日 - 12月31日
汇率基准: 1 USD ≈ 153.14 JPY(按 2026/02/12 实时汇率折算)
1. 核心财务业绩(第三季度单季10-12月)
营业收入折合34亿美金,季度净利润5.73亿美金.
2. 累计业绩(2025年4月 - 12月)
9个月累计净利润:9.58 亿美元.
3. 最重磅发布:全年业绩预测 (至2026年3月底)
铠侠此前一直未公开全年盈利预测,今日财报中首次给出,显示出对市场的极强信心:
预计全年净利润:29.6 亿 ~ 33.5 亿美元
解读: 前三季度净利润总和仅9.58亿美金,这意味着
铠侠预计最后一个季度(2026年1-3月)净利润将暴增至约20亿美金!
相交于上个季度翻4倍!
对比美光和闪迪则为下个季度净利润翻1倍!
恐怖至极!
今年3-4月份存储的财报集体有点恐怖了!
不是较全年,而相较于上个季度全部数倍暴增净利润!
顯示更多

非常深度一篇文章,从GPU架构进化的第一性原理出发,重点解答市场长期担忧的问题:为什么每个GPU的HBM内存需求必然是指数级增长?为什么HBM需求不会像传统DRAM那样停滞或周期性崩盘?记录个要点当做阅读笔记
1. AI推理时代的核心KPI已彻底改变
CPU时代:最高KPI是“performance / FLOPS”(跑分越快越好)。
AI推理时代(尤其是agentic flow兴起后):最高KPI变成token经济学——单位成本/单位电力下的token吞吐量(throughput) + token生成速度。
Nvidia的“AI工厂”本质就是:最低成本输出最多token,同时尽量提高token速度。Pareto frontier曲线要不断向右上方移动。
2. Token吞吐量的第一性原理公式(核心结论)
Token throughput = HBM Size(容量) × HBM Bandwidth(带宽)Batch size(同时处理的请求数) 的瓶颈 = HBM Size
因为每个请求都自带hot KV cache,必须放在HBM里。随着batch增大,KV cache线性增长,HBM容量必须同步线性增长(否则就像接驳车车厢太小,要分多趟拉人)。
每个user的token生成速度 的瓶颈 = HBM Bandwidth
生成每一个token都要多次高频读取HBM里的权重和KV cache。带宽越高,decode速度越快(就像接驳车车门越宽,旅客上下车越快)。
完整类比:
吞吐量 = 接驳车车厢容量(HBM Size) × 车门宽度(HBM Bandwidth)。
只要想让token吞吐量每一代翻倍,HBM的Size × BW乘积就必须翻倍。这是硬件天花板,软件优化无法根本替代。
3. CPU时代 vs. AI时代的本质差异
CPU时代:DDR只是“辅助”,升级极慢(DDR3到DDR5花了15年)。
原因:CPU有大量cache、superscaler等隐藏延迟;日常workload对带宽/容量需求低;app size增长慢。
AI/GPU时代:计算范式彻底转向“memory-bound”(内存受限)。
推理即内存,KV cache + 上下文长度 + 多请求并发,把所有压力都压在HBM上。HBM已从“锦上添花”变成决定性因素。
4. 验证与现实对应
Nvidia从A100 → Rubin Ultra的token吞吐曲线,与HBM Size × BW曲线在对数轴上几乎完全重合(文章提到图二)。
即使利用率(utilization)很难达到100%,HBM仍是整个系统的天花板。老黄必须逼御三家(三星、海力士、美光)不断升级,否则GPU就卖不出去。
5. 软件优化无法改变硬件需求
软件再优化(如LPU把权重搬到SRAM),也只是从另一个维度改善Pareto曲线,硬件天花板仍由HBM决定。就像CPU时代软件再快,CPU厂也必须持续升级跑分一样
顯示更多

AI半导体终局推演2026(I)
当新token经济学范式从GPU算力转移到HBM
本文从从GPU架构进化路线本质出发,解释这个市场长久以来担心的问题:
每个GPU的HBM内存需求为什么一定会是指数增长,为什么HBM需求指数增长不会停滞?
并推导token经济学在当前架构下第一性原理:token吞吐 = HBM size X HBM BW带宽
同时讨论了,为什么GPU的天花板被HBM的两个发展维度所决定
HBM周期性这个话题争议一直很大,乐观派认为AI带来的需求比以前要大的多,但市场主流仍然认为前几次上升周期也有需求每年20%+增长,这次又有什么不一样呢?AI不影响HBM和传统DRAM一样有commodity属性,一旦在需求顶峰扩产遇上需求下行又会重蹈覆辙。
我们可以从算力芯片架构视角,从第一性原理出发,来拆解和推演一下这个问题:为什么这次真的不一样
-------------------------------
历史:CPU算力时代
很久以来,我们都处在CPU主导算力的时代,CPU的最高级KPI就是performance,跑的更快,所以每一代的CPU都用各种方法来提高跑分,最开始是频率上升,后来是架构演进superscaler等等
这个时候为什么DDR不需要很快的技术进步速度?比如DDR3到DDR5竟然经历了15年之久
因为这个时期的DDR的角色是纯粹的辅助,而且辅助功能极弱,以业界经验,DDR的速度即便是提高一倍,CPU的performance一般只能提高不到20%这个量级
为什么DDR带宽速度提高了用处不大?两个原因
1. CPU设计了各种架构去隐藏 DDR延迟,比如superscaler,加大发射宽度,用海量的ROB和register renaming来提高并行度隐藏延迟,一级缓存cache,二级缓存cache,削弱了DDR的带宽速度需求
2. CPU workload对DDR带宽要求并不高,大部分日常负载比如打开网页,DDR带宽是严重过剩的,甚至云端负载
也就是说,在CPU时代,DDR的带宽速度是不太有所谓的,DDR4和DDR5除了少数游戏就没啥差别,甚至JEDEC标准也进步缓慢。
另外,绝大部分app需要一直停留在DDR上的部分并不多,需要的时候从硬盘上调度到DDR即可,app的size增长没那么快,导致对DDR的容量需求也较为缓慢。
所以最近十年来,平均每台电脑上的DDR容量大概从7~8GB变成了23GB,十年只增长了3倍。
而这部分升级缓慢直接影响了营收,size容量计价是赚钱的主要方式,速度的提高只是技术升级,提高size的单价,这两个的升级需求都不大,需求主要是随着电脑/手机数量增长而增长
所以DRAM在带宽速度和容量这两个维度上,一直是都是芯片产业锦上添花性质的附属品,DDR升级带来的边际效用是很低的,跟CPU时代的最高KPI几乎没什么直接联系
--------------------------------------------
而到了genAI 大模型为主导的新时代,计算范式转移让最高级KPI起了根本变化
GPU发展到AI推理的时代,不再像CPU那样只看跑分,最高级的KPI不再是算力TOPS/FLOPS,而是token的成本,特别是单位成本/单位电力下的overall token throuput
其次是token吞吐速度,因为在agent时代,很多任务变成了串行,token吞吐速度成了用户体验的重要瓶颈。
这也是为什么老黄发明AI工厂概念的原因:最低成本的输出最多token,同时尽量提高token吞吐速度
AI训练时代,老黄的经济学是TCO(total cost ownership),买的GPU越多,省的越多
而老黄在推理时代的token经济学是:
AI推理的毛利润很可观,所以逻辑已经转换成:Nvidia GPU是这个世界上让token单价最便宜的GPU,买的GPU越多,赚的越多
最高的KPI变成了Pareto frontier曲线,在提高token 吞吐throughput和提高token速度两个维度上尽量优化
(见图一)
NVIDIA 的 token factory 代际进步,其实是在把整条 Pareto frontier 往右上推,这就是是AI推理这个时代最重要的KPI
----------------------------------
接下来是本文最重要的逻辑链,如何从token吞吐量指数型增长的本质出发,推导出天花板瓶颈在HBM size和HBM 带宽的指数型增长
单卡GPU推理单线程batch size = 1的时代,token吞吐只有一个维度,就是HBM的带宽速度,带宽速度越高,token吞吐越大
但进入NVL72的年代,推理不再是单卡GPU时代,而是72个GPU + 36个CPU整个系统级别的token工厂,把HBM带宽和算力用满,获得极致的token吞吐量
Token 吞吐throughput的增长,依赖两个东西:同时批处理的请求数 X 每个user请求的平均token速度
也就是batch size X per user token 速度
以Rubin NVL72为例,在平均token速度是100 token/s的情况下,同时批处理1920个请求,得到token吞吐量是19.2万token/s 一个Rubin NVL72大概是120KW(0.12MW)的功率,所以得到单位MW能处理1.6M token/s
(见图一)
所以,我们需要想方设法提高这两个参数:批处理数量batch size和per user token的平均速度,这两者相乘就是我们的最高KPI,也就是token的吞吐量
-------
第一个参数:batch size的增长,瓶颈在HBM size
批处理量里的每一个请求req,都会自带kv cache,这部分kv cache是需要存在HBM里的,大小大概在几个GB到数十GB不等 因为hot kv cache是随时需要高频高速读取,所以必须放在HBM里,比如一个大模型的层数是80层,那么每一个token的生成阶段,都需要读取80次HBM里的kv cache
随着批处理数量batch size的增长,会带来hot kv cache的线性增长
又因为这个批处理量的所有请求的hot kv cache,都要放在HBM上,这也就带来了HBM size必须要随着批处理量batch size线性增长
就像是机场接驳车,登机口尽量快的接旅客到飞机,HBM size小了,相当于接驳车size小了,就得多接一趟
结论是:批处理量的数量batch size,瓶颈依赖于HBM size的增长
---------
第二个参数:每个user请求的平均token速度,瓶颈在HBM带宽
大模型decode阶段的速度,瓶颈取决于HBM的带宽速度,因为每生成一个 token,都要把激活的权重和kv cache 读很多遍
LPU的出现,在batch不那么大的情况下,把激活权重这个部分搬到了SRAM上,但是每生成一个 token仍然要从HBM读很多次KV cache。HBM带宽越高,生成每一个token的速度也就越快,基本上是线性对应的
就像是机场接驳车,登机口尽量快的接旅客到飞机,hbm本身带宽速度就像是接驳车的车门有多宽,门越宽,旅客上接驳车越快
GPU的其他配置,都是在适配batch的增长以及要让token compute的速度配平HBM的增长,甚至会用多余的算力来获得部分的带宽(比如部分带宽压缩技术)
—-----
在那个接驳车的比喻例子里
接驳车的车厢大小 = HBM Size(容量): 决定了一次能装下多少名旅客(也就是能同时装下多少个请求的 KV Cache)。车厢越大,一次能拉载的旅客(Batch Size)就越多。如果车太小,想拉100个人就得分两趟,系统整体的吞吐量就上不去。
接驳车的车门宽度 = HBM Bandwidth(带宽): 决定了旅客上下车的速度。门越宽,大家呼啦啦一下全上去了(Decode/生成Token的速度极快)。如果门很窄,哪怕车厢巨大能装200人,大家也得排着队一个一个挤上去,全耗在上下车的时间里了。
旅客的吞吐量 = 接驳车车厢容量 x 接驳车旅客上车速度(车门宽度)
—---------------------------
至此,我们从逻辑上推演出了token经济学的硬件需求第一性原理:
Token throughput = HBM size X HBM Bandwidth
AI推理这个时代的最高KPI,实际上是高度依赖于HBM的两个维度的进步的
如果要维持token throuput每一代两倍的增长,实际上意味着,每一代的单GPU上,HBM size X HBM BW带宽之积要增长两倍!
这也是历史上第一次,HBM内存的size可以影响最高的KPI token throughput!
要验证这个理论,可以把Nvidia从A100到Rubin Ultra这几代的token 吞吐throughput,和HBM size X HBM BW 放在同一个图里比较
(见图二)
可以发现,这两个曲线的走势在对数轴上惊人的一致
HBM size x HBM带宽增长的甚至要比token吞吐量更快,毕竟HBM决定的是天花板,实际上这个天花板增长的利用率utilization是很难达到100%的,也就是说,HBM size x HBM 带宽就算增长1000倍,其他算力和架构的配合下,很难把这1000倍的天花板潜力全部榨干
这条曲线不是巧合,而是系统最优化的必然解
throughput = batch × Bandwidth,这就是token factory 经济学最绕不开的第一性原理
—--------
软件的影响呢?软件的优化会不会降低带宽的需求?降低HBM的需求?
这跟硬件是独立两个维度的,这好像在问,如果CPU上的软件优化了之后跑的更快,是不是CPU就十年不用发展了?反正软件跑的更快了嘛
这样的话,CPU厂还能赚得到钱吗?CPU想要存活下去,只有一条路可走,在标准benchmark,不考虑软件优化,每一代CPU必须要跑分更高,不然就卖不出去
GPU也是一样,软件优化如何,和自己的token吞吐量KPI每年都要大幅进步,是两回事
只要token的需求继续增长,对token throuput的追求就绝不会停止,那么对HBM size X HBM 带宽的追求也不会停止
如果HBM size和HBM 带宽发展慢了,老黄一定会亲自到御三家逼着他们技术升级,因为这就是老黄gpu的天花板,天花板要是钉死了不进步,老黄的GPU还能卖出去吗?
当然了,Nvidia需要绞尽脑汁去从异构计算的架构角度榨取HBM天花板之外的部分,比如LPU就是一个很好的尝试,把Pareto frontier从另一个角度改善了很多 (右半边高token速度的部分)
—--------------------------------------
HBM内存已然告别了那个随波逐流的旧时代,在这条由指数级需求铺就的单行道上,以一种近乎宿命的方式走到了产业史诗的主舞台中央
推理范式第一性原理演化到这一步,只要老黄还要卖GPU,HBM就必须翻倍,而且必须代代翻倍。这是supply side的内生压力,与AI需求无关,与宏观周期无关,与hyperscaler的心情也无关
剩下的问题,只有一个:
当需求被物理锁定为指数增长的时候,供给侧的三个玩家,会不会还像过去三十年那样,亲手把自己再拖回一次周期的泥潭?
顯示更多



美股继续疯,给你一个巴菲特指标判断顶部
01)存储芯片涨疯了
美光大涨15个点,
闪迪大涨16个点,
英特尔大涨13个点,
均创历史新高。
闪迪年初还是200多,现在1500多,7倍多。
相比之下,海力士和三星都算涨幅的弱者了。
那A股的这些存储标的,简直就是蝼蚁。
近期某个新股号称小闪迪,从第一天开始还没一个月已经2.5倍,也算是打出了A股存储的标杆。
只能说,财富效应如此集中,真的是胆大者的盛宴。旱的旱死涝的涝死,如果你最近处于焊死阶段,多想想自己的问题。
你是蹲对了不敢上仓位,还是蹲错了没有切换?
如果蹲对了但仓位小,那很简单,每一次回踩MA5的时候都要珍惜。
如果蹲错了,什么时候做切换?也很简单,等美股消停的时候,回调就是分歧时间。
02)蹲错的人有两个选择
蹲错的懒人有两个选择。
一个是蹲对应的行业类ETF,比如科创人工智能,或者本周又开始热门的航天ETF、卫星ETF。
一个是无脑买入QDII基金,即间接配置美股。大部分美股基平均收益都20多个点了,这还是弱的。
精准踩对美股存储和光的QDII基金,这两个月来都40多个点了。
你可以自己在某宝搜索QDII,看收益曲线就知道我没瞎说。
只可惜因为各种限购,导致每天收益只有几杯奶茶。
但凡每天有个10000额度的,收益都不敢想有多高。
后续下半年QD额度放开后,我会给大家做建议。
03)海外谈泡沫的声音更大
现在别说A股感觉有牛市氛围了,美国的分歧更大。
如果你经常出去看观点,你会发现海外谈泡沫的声音更大。
对冲基金传奇人物Paul Tudor Jones表示,当前环境与1999年高度相似,但他认为牛市或许仍有一至两年的续航空间。
不过一旦估值继续膨胀,最终的调整将令人窒息。
数据显示,费城半导体指数在过去的28天中有24天上涨,涨幅高达63%。这种涨法,说没泡沫你自己信吗?
04)巴菲特指标:一个简单的天花板测量工具
看完这些泡沫讨论是有帮助的,因为你能很清晰看到美股的天花板在哪里。
简单做个科普:巴菲特指标。
2001年巴菲特提出,股市总市值除以GDP,超过2倍即高度危险。
当下的数据:2025年美股GDP约30万亿,5月美股总市值约75万亿。目前美股总市值距离3倍GDP,还有20个点左右涨幅。
刻舟求剑的数据:
2000年互联网泡沫前指标达146%,随后纳斯达克暴跌78%;
2008年金融危机前突破110%,标普500一年内腰斩;
2022年初指标超200%,随后标普500年度下跌19%,创2008年以来最大跌幅。
所以这个巴菲特自己提出的指标警告风险,结合巴菲特疯狂囤积了3973亿现金,你能理解他为啥不享受泡沫,而是疯狂囤现金了吗?
巴菲特作为投资常青树,知行合一是非常重要的。他不知道哪天泡沫破裂,但他知道一定会破裂。
-----
看完是不是心惊肉跳?是的,活在上涨恐惧中的美国机构就是这样的心态。
但乐观者的观点是:站在新一轮工业革命之前,一切皆有可能。
你是愿意做一个踏空的悲观者,还是愿意做一个泡沫中的乐观者呢?
我的选择是:既在泡沫中享受上涨保持定投,又随时回调抄底。
仓位管理和止盈纪律,比判断顶部更重要。
顯示更多


【国金具身智能】特斯拉机器人进入备产阶段,关注核心标的订单进展
事件:机器人板块近期回暖,绿的谐波盘中一度涨幅达17%。
解读:(1)特斯拉S/X产线五月结束生产,开始转为机器人产能,产业链发生实质进展。
(2)5月初开始财报季结束,对短期业绩担忧结束。
(3)据统计,机器人板块历史回撤30%后,后续迎产业链落地进展多数将带来大幅上涨机会 。
相关资料:
1 机器人板块年报一季报总结:产业仍在突飞猛进,等待拐点到来#小程序#://国金证券研究服务/U97FdyboEBNQDwI
2 再次提示绿的谐波超预期机会
id=468938&UILoaded=378&UIGlobal=106&UIScrolled=378&shareUserId=3177646&pipId=record_468938
投zi建议:Q1资本市场扰动因素增加,但是目前产业基本面进展整体符合我们预期,且我们认为,资本市场的元叙事跟产业实际情况有较大预期差。我们维持26年年度策略观点不变,即:26年是人形机器人0-1兑现阶段,龙头公司供应链、技术都会趋于收敛。
(1)#特斯拉链的收敛:特斯拉链已经迭代4年,目前硬件供应链趋于收敛的拐点。围绕确定性和空间,重点关注:拓普集团、三花智控、绿的谐波、五洲新春、蓝思科技、长盈精密、浙江荣泰、金沃谷份、恒勃谷份、领益智造、均胜电子、领益智造、科森科技(计算机组覆盖)等。#
(2)#技术迭代与收敛:重点关注谐驱动新技术(波磁场电机、GaN)、灵巧手(电子手套、新型基材)、新材料(peek)、高端轴承等。重点关注:宁波华翔、英诺赛科、日盈电子、泛亚微透、宏微科技、岱美谷份等。#
(3)#海外其他供应链的机会:苹果、谷歌、OpenAI、Figure等都陆续迈入0-1,重点关注兆威机电、银轮谷份、汉威科技以及电子链标的相关机会。#
(4)#国内本体和应用垂类机会:宇树、智元、乐聚、银河通用等陆续上市,关注供应链亿嘉和、翔楼新材、东方精工、均胜电子、天奇谷份、咸亨国际、上纬新材、优必选(机械组覆盖)等。#
(5)围绕长期确定性,布局“优质格局”的标的:绿的谐波(谐波减速器龙头)、奥比中光(深度相机龙头)、英诺赛科(氮化镓龙头)、宁波华翔(peek龙头)。
顯示更多
生成式AI往代理式AI迁移中,新的卡脖子环节又出现了,这次是CPU。之前市场关于算力紧缺的讨论都在GPU、HBM、光模块、电力等环节,其实对于CPU的关注比较少。其实Cpu的紧缺传了一段时间了,看最近英特尔、AMD走势最核心驱动力就是来自cpu开始出现紧缺了,甚至连过往不怎么受待见的港股联想集团,最近两周走的也很强。
1、为什agentic ai时代CPU占比会扩大?
传统AI(主要是大模型训练/推理)高度依赖GPU,因为Transformer的核心是并行矩阵运算,GPU擅长高吞吐的并行计算。这时CPU主要只负责“辅助”:数据路由、内存压缩、GPU调度等,导致数据中心CPU:GPU比例很低(典型1:4~1:8,甚至1颗CPU管8颗GPU)。CPU利用率低,基本是配角。
Agentic AI完全不同,它不是单次“问答”,而是自主多步循环(Planning → Tool Use → Act → Observe → Reflect → Iterate),涉及:
1)编排:调度子任务、多智能体协作、分支逻辑、重试机制。
2)工具调用:网页搜索、API调用、代码执行、数据库查询、向量检索(RAG)、文件处理等。
3)其他CPU密集任务:上下文管理、KV Cache处理、强化学习(RL)仿真评估、数据预/后处理。
这些任务高度串行、I/O密集、逻辑分支多,GPU并不擅长(甚至会闲置)。研究显示:工具处理阶段在CPU上可占总延迟的50%~90.6%(GPU在等待CPU)。Agentic工作流中CPU动态能耗占比可达44%,比传统AI高3~4倍。
简单说,Agentic AI把“思考”交给GPU,但把“做事/协调”交给CPU。CPU从“管家”变成了“总指挥”,必须大幅增加才能让整个系统高效运转。这就是CPU占比扩大的核心驱动(Intel、AMD、Arm、TrendForce等一致观点)。
2、CPU成为新紧缺环节的现实证据
今年Q1 Intel/AMD服务器CPU交期已经拉到6-12周,部分型号基本售罄,价格也提了10%以上。厂商自己都说“demand far exceeded expectations”。不是产能不够,而是Agentic AI把CPU从“可有可无”直接干成了“必须配足”的总指挥。
数据中心项目现在除了电力,就是CPU卡脖子最严重。传统x86(Intel/AMD)高功耗+产能紧张,供应链直接打爆。
3、CPU缺口会有多大?
行业共识是CPU:GPU比例将显著拉近,CPU需求大幅提升:从传统1:4~1:8(CPU:GPU)转向1:1~1:2(部分场景甚至1.4:1,即CPU比GPU还多)。看之前Arm估算,每GW算力需要的CPU核心从3000万激增到1.2亿(4倍增长)
CPU算力份额:在Agentic工作流中,CPU承担的算力比未来机架/集群可能从“GPU主导”转向更平衡,甚至出现专用CPU rack来支撑Agentic编排;AMD/NVIDIA新一代平台已开始按1:2~1:4设计
这就带来了CPU需求的真实拐点,是实打实的硬件重构。
4、特别要说下ARM服务器CPU会更受益一些?
Agentic AI最需要的就是“高核心数+低功耗+稳定串行处理”。ARM天生多核可扩展、perf/watt领先:Arm AGI CPU(136核,TDP仅300W)对比x86同规格功耗低40%+,每机架性能直接翻倍。风冷机架就能塞8000+核,液冷更能到4万+核,完美解决数据中心的“功耗墙”。
更狠的是生态大转向:AWS Graviton、Google Axion、Microsoft Cobalt早就自研ARM,云巨头集体“去x86化”。Arm 3月直接下场自研AGI CPU(首款量产芯片),Meta、OpenAI、Cerebras都是首发伙伴,OEM有联想、Supermicro。
Counterpoint预测:AI ASIC服务器CPU里,ARM份额从2025年25%干到2029年90%。Arm自己说,这波能把数据中心CPU TAM从30亿版税干到1000亿+,未来几年服务器CPU营收很可能超手机,成为最大增长极。
看下周和5月初英特尔、amd的财报电话会上,cpu实际出货量的变化、以及cpu的真实价格变化。这能说明真的有多紧缺。
5、CPU紧缺哪些公司会受益?
梳理了下哪些公司会受益,后续关注起来:
美股最核心:
Intel (INTC)ntel 依然是服务器 CPU 市场的霸主。短缺潮会提升其过往型号的利润率,且其 Gaudi 与 Xeon 的组合在代理推理端有强劲需求。
AMD (AMD):理由:在 Agentic AI 服务器市场,AMD 的 EPYC 处理器因多核心优势和高性价比,目前在云厂商中的市占率持续提升,是 GPU+CPU 均衡配置趋势下的首选。
Arm Holdings (ARM):越来越多的云厂商(亚马逊、微软、谷歌)开始自研基于 ARM 架构的 CPU。无论谁赢,只要 Agent 需求推高 CPU 核心数,Arm 的授权费就会大涨。
港股(制造与分销关键点)
中芯国际 (0981):虽然其在最先进制程受限,但大量非核心逻辑控制芯片(支持 CPU 运作的辅助芯片)和中端 CPU 的需求外溢,会显著提升其产能利用率。
联想集团 (0992):全球第一大服务器与 PC 厂商。在短缺潮初期,拥有强大供应链管理能力和库存的大厂能通过提价和保证供应,抢占更多政企市场份额。
A股(国产替代与配套产业链)
海光信息 (688041):国产 x86 服务器 CPU 的龙头。在 Agentic AI 时代,由于其架构与全球生态兼容性最好,国内算力中心在补齐 CPU 短缺时,海光是第一顺位替代品。
龙芯中科 (688047):自主架构 CPU 的代表。随着国产自主可控需求增强,在党政和关键基础设施的 Agent 应用中受益。
深南电路 (002916) / 沪电股份 (002463):理由:配套受益。CPU 核心数增加和 GPU+CPU 配比调整,要求更复杂的 PCB(印制电路板)和封装基板,这些公司是全球高端服务器 PCB 的主力供应商。
澜起科技 (688008):内存接口芯片龙头。只要 CPU 多,内存条就多。Agent 时代对内存带宽要求极高,其 MRDIMM 和内存接口芯片是 CPU 性能爆发的必需品。
投资逻辑核心其实两点:
1)量价齐升:CPU 厂商(AMD, Intel, arm、海光)最直接。
2)卖铲子的人:由于 Agent 需要高带宽,内存配套(澜起)和先进封装/基板(深南)的需求甚至比 CPU 本身更稳。
顯示更多

2月初开始聊的“春劫行情”是不是要告以段落了?今天对于市场来说算是大反转,战争爆发以来第一次真正进入谈判阶段,当然不是说后面就一帆风顺,如早上聊到的伊朗的条件还是很苛刻,有几个条件川普很难接受,之后应该还会有反复,谈判反复可能就是市场再恐慌的时候了,但那时候不应该是我们再恐慌的时候,是可以逢低买入的时候。
之前在这里聊到
这里还有一个隐含时间条件是:美国对外军事行动时间期限就是60天源于1973年的《战争权力法》,60天之内总统可以决策。超过60天就需要国会授权,现在这种情况下不仅民主党即使共和党内也有不少议员是反对的,简单多数可能都通不过。所以越往后市场也会看到这一点、战争本身对市场的影响开始变小。
上周五这里
1)60天的对外战争时间期限;
2)4月中下旬是美股一季度财报季,财报季最重要的就是验证一季度火热的AI代理热潮是不是能带动大科技云业务的火爆,毕竟算力即收入。如果能带动,市场对AI质疑可能就转化成验证,那么情况又会不一样了;
3)美股还是基本面第一位的,个股大幅杀跌进入高性价比区间后、是可以忽略大盘建仓的。上周其实已经在逐步买入了;
4)对于大饼、2月初6万左右买过一些,期待再能等到好的机会。4月中美国保税季、流动性会收紧、可能会再出现好机会;
看好的美股板块
1)AI半导体产业链上的观念环节都很看好,如存储、光模块,这俩也是去年十一二月上车厚一直拿着没减仓的板块。
其他只要是算力链条上卡脖子环节都值得关注;
2)大科技估值杀到位,也是高性价比。之前的资本开支战争的推文有聊到大科技商业模式变化带来估值中枢下移,但并不是说完全不看好。只要估值杀下来还是有性价比的;
3)看好太空经济,今年有Spacex上市和登月能带动一波、之前也有推文聊过。
4)跟加密相关股票板块:hood、coin、circle等;
后面可能就不再说“春劫行情”,不是说行情就此反转,而是可以多关注个股基本面了,后面伊朗局势的反复对市场还会有影响、但是已经不是唯一逻辑主线了。
顯示更多