檢索結果 TPU
TPU 貼吧
一個關鍵字就是一個貼吧,路徑全站唯一。
用戶
未找到
包含 TPU 的搜尋結果

谷歌的tpu在hbm存储用量上将增长6.8倍,当时谷歌还拿小作文跟三巨头谈判长约😂
目前算上三巨头的扩产产能也远远跟不上他们的规划需求增量。
顯示更多



谷歌的tpu芯片⽤例与 GPU 相⽐略有局限,在特定用例上比如推理方面,谷歌tpu芯片提供⾼达 1.4 倍的每美元性能提升,这对于可能尝试使⽤ GPU ⽽不是 TPU 的客户来说是⼀笔相当可观的节省.
同时在搜索检索速度方面, TPU 提供的速度优势,TPU 在训练动态模型的速度⽐ 英伟达GPU 快 5 倍.
顯示更多
还得是股神,最近谷歌的tpu芯片大火,几个英伟达的ai芯片大客户都选择了至少10-20%原本给英伟达的份额分给了谷歌tpu芯片.


不知不觉,过去2周写了很多关于Google #TPU# 的文章,既有技术干货也有商业思考,整理TPU系列文章如下:
1️⃣谷歌重要产品发布介绍分别是 专用于训练的TPU 8t芯片以及Virgo 网络。
2️⃣300万片TPU背后的产业链:
3️⃣为了适应模型发展,第八代TPU设计中,谷歌的软硬件和网络解决方案:
4️⃣Anthropic 订购TPU,他和谷歌的股权投资历史
5️⃣Google TPU 8t和英伟达GB300机架级性能对比
6️⃣TPU封装
7️⃣TPU对英伟达的冲击
8️⃣TPU对谷歌财报未来贡献
顯示更多


不管是英伟达的gpu还是谷歌的tpu都是得给台积电来加工,台积电才是终极金铲子吧.
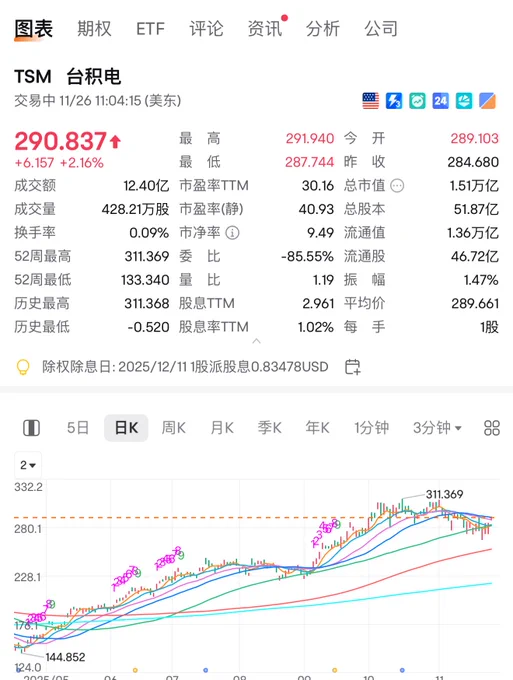
还得是股神,最近谷歌的tpu芯片大火,几个英伟达的ai芯片大客户都选择了至少10-20%原本给英伟达的份额分给了谷歌tpu芯片.
按照 $GOOG 财报会中透露的时间节点,26年底tpu出货,27年放量。
对应的 $MRVL 连续爆拉时间可能就在9月左右开始直到27年。因为tpu没有大规模放量现在市场看不太清楚mrvl的潜力。
顯示更多

谷歌这个财报最利好 $MRVL
谷歌用tpu侵蚀了英伟达的市场版图,
而最新款的推理TPU和内存MPU,俩个未来需求量最大的芯片设计是跟 $MRVL 合作,
谷歌利润暴增,自然 $MRVL 作为供应商肯定利润也少不了。
顯示更多

谷歌这个财报最利好 $MRVL
谷歌用tpu侵蚀了英伟达的市场版图,
而最新款的推理TPU和内存MPU,俩个未来需求量最大的芯片设计是跟 $MRVL 合作,
谷歌利润暴增,自然 $MRVL 作为供应商肯定利润也少不了。
顯示更多
现在 $MRVL 156刀太便宜,为什么看好 。
要从谷歌在 TPU 供应链上采取的“分而治之”的策略说起。
谷歌跟博通的合作是主要负责高性能训练级的TPU。
而谷歌跟 $MRVL 的合作是推理型TPU和新增的内存处理单元MPU。
很明显在AI带来的token经济时代,推理和内存是最大的需求端反超了训练需求。这个变化很快就会反馈在今年下半年的 $MRVL 财报业绩中, $MRVL 的 AI 业务刚进入爆发期,谷歌的订单(预计 2026-2027 年出货达数百万颗)对其业绩的边际拉动作用远大于博通。
同时我们可以分析一下从为什么谷歌会找 $MRVL 来合作设计推理TPU和内存MPU。
为了降低延迟,现在的AI服务器从铜互联进化到光互连,未来的硅光技术会成为主流。
而在这方面,光互连和芯片设计都精通的
$MRVL 进入谷歌 TPU 供应链就是谷歌的必然选择。对mrvl来说这本质上就是为了下一代“光电融合”架构做铺垫,不仅是在帮谷歌“画电路图”,它实际上是在推销一套“全光互连的计算底座”。在这种趋势下,芯片公司与通信公司的界限正在模糊, $MRVL 正在试图定义 1.6T 乃至 3.2T 时代的 AI 连接标准,将原本属于模块厂“#中际旭创# #新易盛# ”的一部分利润(即集成和测试的溢价)收归己有。
顯示更多

$MRVL 收购瑞士光学公司Polariton,为下一代3.2T光模块提前作技术储备。
$MRVL 绝对的大帝之姿,未来20倍机会,市值还没中际旭创大。
它还是仅次于博通的ASIC芯片设计公司。
俩个赛道都是天花板万亿美金。
现在这个市值太便宜了。
顯示更多


🔥 前AMD高管深度拆解:ASIC战局与芯片巨头的隐秘关系
⠀
$NVDA 之外的世界,正在悄悄重组 👇
⠀
1️⃣ 为什么 $GOOGL TPU 需求暴增?
⠀
市场迫切需要 $NVDA 以外的选择
⠀
推理端需求爆发,TCO成为新战场
⠀
前几代TPU主打训练,现在全面转向推理
⠀
2️⃣ 推理时代的新指标
⠀
不再只追求原始算力和最大功耗
⠀
转向每瓦性能和每美元性能
⠀
效率才是下一轮竞争的核心
⠀
3️⃣ $GOOGL TPU 背后谁在撑场?
⠀
核心架构:$GOOGL 自研
⠀
SerDes IP 等关键知识产权:来自 $AVGO
⠀
两家深度绑定,不是简单的甲乙方关系
⠀
4️⃣ $MRVL 的下一张牌
⠀
$GOOGL 将与 $MRVL 合作开发下一代内存处理单元 MPU
⠀
最大瓶颈:ASIC与内存之间的数据传输速度
⠀
解法:把部分计算直接卸载到内存,减少吞吐瓶颈
⠀
5️⃣ $INTC 的逆袭机会
⠀
$GOOGL TPU 第九版将采用 $INTC 的 EMIB 封装技术
⠀
$META 计划2027年用 $INTC 开发自研ASIC
⠀
这些都是代工订单,不直接影响 $AVGO 和 $MRVL 的设计业务
⠀
但 $INTC 代工端将显著受益
⠀
💡 一句话总结
⠀
AI芯片格局正在从 $NVDA 一家独大
⠀
演变成 $GOOGL · $AVGO · $MRVL · $INTC 多方分食
⠀
每一层都有赢家,关键是你蹲在哪一层
⠀
❓ 你最看好哪家从这轮ASIC浪潮中获益最多?
⠀
评论区告诉我 👇
顯示更多
