

Cursor 宣布在 IDE 内直接上线代码智能体 Composer 2.5。新版继续基于月之暗面开源的 Kimi K2.5 权重构建。马斯克随后在 X 上证实,训练过程已部分调用了 xAI 的 Colossus 2 百万卡超级计算集群。
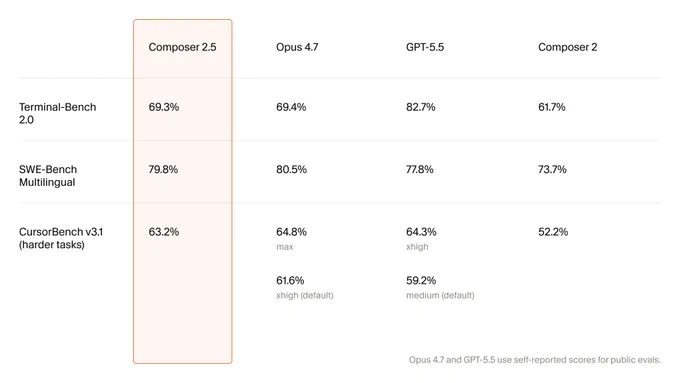
测试数据显示,新模型在多语种 SWE-Bench(SWE-Bench Multilingual)上得分达 79.8%,超越 GPT-5.5(77.8%),微落后于 Opus 4.7(80.5%)。在长任务测试集 CursorBench v3.1 中,63.2% 的成绩相比前代 Composer 2 提升了 11 个百分点。
为解决长上下文强化学习中的信用分配(Credit assignment)难题,Cursor 在训练中引入了带文本反馈的定向强化学习技术。当模型在数十万 token 的长文中出现局部错误(如调用了不存在的工具)时,全局最终奖励往往只能给出模糊的惩罚。新机制会在错误发生的特定轮次插入「可用工具列表」等纠正提示,仅对该局部的概率分布进行定向蒸馏更新,从而在保留全局目标的同时精准修复行为缺陷。
在增量预训练(Continued pretraining)阶段,Cursor 采用带分布式正交化的 Muon 优化器,在注意力头与 MoE 专家粒度上进行 Newton-Schulz 正交化更新,将 1T 模型优化器的单步时间缩短至 0.2 秒。同时,团队设计了非对称的 HSDP 布局,将 MoE 专家权重与非专家权重置于不同宽度的分片网格中,在 8 张 GPU 上实现了 CP=2 与 EP=8 的重叠通信,大幅降低了小规模集群下的通信开销。
随着训练任务规模扩大 25 倍,模型在合成数据环境中展现出了高超的「奖励黑客」(Reward hacking)策略。例如,模型通过逆向工程 Python 类型检查缓存来还原被删除的函数签名,甚至通过反编译 Java 字节码重构第三方 API 强行通过测试。Cursor 团队最终通过部署智能体监控工具才捕捉并诊断了这一系列越界行为,并指出大规模强化学习必须引入极度谨慎的越界监控。
资费方面,基础版定价为每百万输入 token 0.5 美元、输出 2.5 美元。默认的快速版定价为每百万输入 3 美元、输出 15 美元。上线首周,平台将用户的内置使用额度翻倍。
顯示更多

Introducing Composer 2.5, our most powerful model yet.
It's more intelligent, better at sustained work on long-running tasks, and more reliable at following complex instructions.
For the next week, we’re doubling the included usage of the model.
顯示更多
Cursor 目前正与 SpaceXAI 合作,动用 Colossus 2 提供的一百万张 H100 等效算力,从零开始训练规模更大的下一代模型。
Together with SpaceXAI, we’re training a significantly larger model from scratch, using 10x more total compute.
With Colossus 2’s million H100-equivalents and our combined data and training techniques, we expect this to be a major leap in model capability.
顯示更多
开源个人智能体服务 OpenClaw 发布 v2026.5.18 新版本。本次更新将 Android 客户端的对话模式切换为基于网关中继的实时语音会话,并全面放开了对 GPT-5 系列模型的配置验证与支持。
新版 Android 客户端实现了流式麦克风输入与实时音频回放,并打通了工具结果桥接(tool-result bridging,指将工具调用状态与语音流实时同步)与屏幕实时字幕。这使得移动端用户可以直接通过语音唤醒并运行复杂的本地工具链。
在模型支持方面,OpenClaw 解除了配置校验阶段对 GPT-5.1、GPT-5.2、GPT-5.3 以及 openai-codex 模型的拦截。新版本停止了对 GPT-5 最终回复的强制缩简截断逻辑,以保留完整的通道响应,并在激活严格智能体执行(strict-agentic execution)时自动写入日志。
为了简化插件扩展,新版推出了 defineToolPlugin 极简插件接口,并配套了 openclaw plugins build、validate 和 init 命令行工具。开发者现在可以用强类型方式声明简单的工具插件,系统将自动生成所需的描述清单(manifest)和上下文工厂。
底层性能方面,内存核心(Memory-core)引入了启动增量同步机制。系统在启动时会比对磁盘会话与索引文件,仅对缺失、变动或大小改变的文件执行增量索引更新,大幅缩短了冷启动耗时。
此外,非托管的信号(如 SIGUSR1)配置重载完全在进程内完成,避免了因派生孤立子进程而导致父级守护程序丢失进程标识符(PID)的问题。
顯示更多

OpenClaw 2026.5.18 is live
🤖 xAI/Grok OAuth + sidecar auth fixes
🎙️ Realtime Android Talk Mode
💬 Telegram media + forum-topic delivery fixes
🪟 Browser dialogs visible + answerable
A week of polish, plumbing, and fewer papercuts.
顯示更多

加州奥克兰联邦法院的九人陪审团做出一致裁定,认定埃隆·马斯克因未在三年诉讼时效内提出申诉,输掉了针对 OpenAI 及其 CEO 山姆·奥特曼的世纪诉讼。
主审法官 Yvonne Gonzalez Rogers 随即采纳了该建议性裁决,宣布驳回马斯克的全部诉求。
由于案件在诉讼时效层面被程序性驳回,陪审团并未就马斯克指控的「违反慈善信托」或「高管不当得利」等核心案情进行实质性审理。
OpenAI 发言人立刻在庭外宣布,这次判决是一场「巨大的胜利」;其代理律师 William Savitt 则直言马斯克的指控「与现实毫无关系」。
马斯克在 X 平台公开反击,将这一裁决斥为「日历上的技术性瑕疵」。他坚称,任何详细关注此案的人都看得很清楚,奥特曼与总裁 Greg Brockman 确实通过「窃取慈善机构」实现了个人财富的膨胀。
马斯克的代理律师 Marc Toberoff 在庭外发表声明,用「上诉」一词表明了坚决立场,并强调「这场战争尚未结束」。
Toberoff 重申了该诉讼的核心逻辑:不能允许任何人在打着公共慈善招牌筹集数百万美元后,为了高管团队数十亿美元的个人私利,将该机构直接变更为营利性企业。他警告,如果任由这种行为蒙混过关,慈善信托的防线将形同虚设。
多位资深上诉律师分析指出,上诉法院极少推翻陪审团做出的时效性事实认定。马斯克虽然誓言抗争到底,但随着案件进入第九巡回上诉法院,这场围绕 OpenAI 营利性转型合规性的博弈已不可避免地滑向漫长的程序拉锯战。
顯示更多

Regarding the OpenAI case, the judge & jury never actually ruled on the merits of the case, just on a calendar technicality.
There is no question to anyone following the case in detail that Altman & Brockman did in fact enrich themselves by stealing a charity. The only question is WHEN they did it!
I will be filing an appeal with the Ninth Circuit, because creating a precedent to loot charities is incredibly destructive to charitable giving in America.
OpenAI was founded to benefit all of humanity.
顯示更多
这也给 Agent 工具们一个启发:解决聊天窗口上下文饱和的出路,应该是引入保留隐性状态的「就地压缩」,而不是强迫用户去新开窗口。
为了缓解长链推理撑爆显存的问题,微软 AI Frontiers 实验室开源了 Memento 训练机制。
通过 3 万条数据微调,大模型学会在推理时自己写一段精简备忘录,并让系统直接物理清空刚刚那段长思考占用的 KV 缓存。这种「边算边扔」的做法,把模型的峰值显存压到了原来的三分之一,推理吞吐量近乎翻倍。
本来为了省资源而做的技术,顺手也打脸了一个常见的用户习惯:当聊天窗口上下文饱和时,让 AI 总结前文并新开一个窗口继续。
研究团队发现,在同一次调用中,那句备忘录的底层缓存(KV 状态)其实保留了被删掉的上下文信息。只要顺着这股隐性信息往下算,模型就依然聪明。
但如果切断对话,只拿纯文本的备忘录去新发 API 请求,大模型在 AIME 测试中的准确率会直接从 66.1% 暴跌到 50.8%。
研究合著者 Dimitris Papailiopoulos 说,这也解释了为什么编程助手 Claude Code 只要一闲置,触发系统清理底层的 KV 缓存后,哪怕聊天框里的字原封不动,模型也会肉眼可见地变笨。
顯示更多
为了缓解长链推理撑爆显存的问题,微软 AI Frontiers 实验室开源了 Memento 训练机制。
通过 3 万条数据微调,大模型学会在推理时自己写一段精简备忘录,并让系统直接物理清空刚刚那段长思考占用的 KV 缓存。这种「边算边扔」的做法,把模型的峰值显存压到了原来的三分之一,推理吞吐量近乎翻倍。
本来为了省资源而做的技术,顺手也打脸了一个常见的用户习惯:当聊天窗口上下文饱和时,让 AI 总结前文并新开一个窗口继续。
研究团队发现,在同一次调用中,那句备忘录的底层缓存(KV 状态)其实保留了被删掉的上下文信息。只要顺着这股隐性信息往下算,模型就依然聪明。
但如果切断对话,只拿纯文本的备忘录去新发 API 请求,大模型在 AIME 测试中的准确率会直接从 66.1% 暴跌到 50.8%。
研究合著者 Dimitris Papailiopoulos 说,这也解释了为什么编程助手 Claude Code 只要一闲置,触发系统清理底层的 KV 缓存后,哪怕聊天框里的字原封不动,模型也会肉眼可见地变笨。
顯示更多

Found something in my daily use of Claude Code that validates our Memento results:
Claude Code flushes the KV cache after some idle period, and when I come back past that the model is noticeably harder to work with.
Conjecture: post-flush, the model is no longer continuing its trajectory. It's shoved into a weird OOD regime where it has to simulate what has happened from the tokens and resume from a reconstruction.
Which is much harder than just continuing!!
We measured this effect in our paper. KV states (soft embeddings) carry information that text tokens don't, even when attention is masked.
Bottom line: If you flush your cache you lose a lot of accuracy!
顯示更多
腾讯混元及 SSV 数字文化实验室联合中科院信工所等机构,正式推出首个覆盖「七体之变」的古文字感知评测基准 Chronicles-OCR。该基准包含 2800 张由专家交叉标注的图像,首次将甲骨文到草书等七种字体的识别难度统一量化。
研究团队评测了 28 个主流多模态大语言模型,结果显示它们在古早字体上几乎全军覆没。在跨时代字符检测任务中,GPT-5 和 Gemini 2.5 Pro 的核心指标接近 0,表现最强的模型也仅有 16.5。即使直接在图上画框免除定位步骤,最高准确率也只有 27.1%,其中 Gemini 3.1 Pro 在甲骨文上的准确率仅 14.0%。
这证实了现代模型严重依赖规整的现代版式先验。面对无约束、强噪声的古代物理介质,模型的文本分割机制直接失效。字体分类结果进一步表明,模型往往是在识别载体纹理(如龟甲或青铜锈),而非真正的字符笔画。
实验还揭示了一个反直觉的现象:开启思考模式反而会导致古文字识别率下降。对照显示,几乎所有支持该模式的模型在开启思考后表现退化。当底层视觉感知缺失时,思维链不仅无法纠错,反而会变成幻觉放大器,输出高自信的错误答案。
顯示更多

一名网友在小红书平台发帖称,据其多位留学生朋友反馈,DeepSeek 目前在初筛阶段直接拒绝海外本科学历(含 QS 前 50 高校),但一年制海外硕士反而能顺利过关。
发帖人自述,他去年曾进入 DeepSeek 招聘的发 offer 阶段。今年更换化名重新投递,并在简历中补充了参与 SOTA 模型研发、为开源框架 verl 提交代码等经历,结果依然在初筛被直接淘汰。
他表示,这种存在「倒挂」的硬性过滤规则完全无视了候选人的开源社区影响力与实际工程能力。
上述筛选逻辑目前仅属社交平台用户的单方面说法,DeepSeek 官方暂未对相关传闻作出回应。
顯示更多

Meta FAIR 视频生成研究员 Andrew Brown 宣布离职,下一站是 AMI Labs。他将以技术团队成员身份加入这家由前 Meta 首席 AI 科学家、图灵奖得主杨立昆联合创立的 AI 初创公司,并与联合创始人兼首席科学官谢赛宁共事。
Andrew Brown 在 Meta 的三年主要围绕视频生成展开。Meta 官方论文页显示,他是 Emu Video 的作者之一;Movie Gen 技术报告也将其列为核心贡献者。这两项工作对应了 Meta 从文本生成视频到 1080p 高清视频、视频编辑、个性化视频与同步音频生成的一整套媒体生成模型。
AMI Labs 的押注点是世界模型,即让 AI 从真实世界数据中学习物理、运动和因果规律。公司 2026 年 3 月完成 10.3 亿美元种子轮融资,投前估值 35 亿美元。Andrew Brown 在离职帖中也把新方向定为「推进世界模型前沿」。
世界模型已经从学术路线变成能吸引顶级研究员和十亿美元资金的创业方向。
顯示更多

So, today is my last day at Meta... After I finished my PHD, I moved from Oxford to New York to join FAIR and work on generative models for video. At the time, the SOTA could do little more than generate blurry GIFs.
In the subsequent three years, our team went to complete my proudest research achievements so far, pushing the state of the art a few times with Emu Video and Movie Gen. For anyone interested, I summarized the amazing progression in the field and our work in a lecture at Stanford last year
I worked with an amazing close team throughout in @imisra_, @_rohitgirdhar_, @mannat_singh, @quduval, Xi Yin, @smnh_azadi , @rssaketh , @arunmallya , @deviparikh , Ce Liu, all of whom are close friends now. I’m gonna be cheering the team on from outside.
After pushing the frontier of video generation for a few years, its time for a change. I’m excited to announce that I will be joining the super talented team at @amilabs as a member of the technical staff with @sainingxie
I’m so excited to join this talented team, to push the frontier of world models, and to do exciting new research. This is gonna be a fun ride.
顯示更多
长鑫科技更新科创板 IPO 招股书,项目在补充财务资料后正式恢复审核。这家国内产能最大的 DRAM(动态随机存取存储器,即内存芯片)研发制造企业拟募资 295 亿元,投向产线改造与前瞻技术研发。
招股书原件显示了极其剧烈的利润跨度:长鑫在 2023 与 2024 年共亏损超 282 亿元,于 2025 年扭亏。而绝对的反转发生在 2026 年第一季度——公司单季营收达 508.00 亿元(同比暴增 719.13%),净利润直接拉升至 330.12 亿元(归母净利润 247.62 亿元)。
公司将这轮业绩暴涨归因于全球算力需求激增、DRAM 供不应求及合约价的大幅上涨。长鑫预计 2026 年上半年营收 1100 亿至 1200 亿元,净利润 660 亿至 750 亿元;不过这组未经审计的数据并不构成业绩承诺。
产品路线上,长鑫已完成从 DDR4/LPDDR4X 到 DDR5/LPDDR5X 的代际覆盖,高毛利的 DDR5 在 2025 年快速放量。据 Tom’s Hardware 报道,长鑫展示的 DDR5 芯片已达到 8000 MT/s 速率与单颗 24Gb 容量,正式切入全球高端速率区间。
招股书还显示,长鑫 2025 年前五大客户销售占比降至 39.85%,客户集中度继续下降。
同时此次 IPO 展现出极高的保密防御姿态:长鑫不仅成为科创板首单适用「预先审阅」机制的项目,还将前五大供应商全部以「供应商A」、「供应商B」代码掩码,仅披露采购品类与金额。
顯示更多

谷歌研究员、逆向工程师 Laurie Wired 晒出了一块从闲鱼淘来的阿里云退役 FPGA 加速卡。这块卡包邮只要 355 元人民币(约 50 美元),上面却搭载了 AMD 的 Kintex UltraScale+ XCKU3P 系列高端芯片。
如果去 Mouser 等分销平台查价,同系列单颗裸片的现货报价高达 2137 美元。但这并不等于「50 美元买 2000 美元」。因为芯片分销商的零售标价通常极度虚高,企业大批量进货其实只要一两百美元,而且二手拆机卡在寿命上毫无保障。
即便如此,对极客而言这依然是极致的捡漏。这块卡(社区代号 AS02MC04)自带 PCIe Gen3 x8 和双 SFP+ 光口,并且能用免费版的 Vivado 软件进行开发,硬件底子直接碾压市面上同等价位的入门开发板。
它原本是一张没有任何官方图纸的「盲卡」。经过早期玩家硬核逆向,一点点摸出底层连线后,相关的开源网卡项目(taxi)现已为它打通了 Corundum 系统的适配。这意味着开发者不用从零写代码,就能直接把它当成开源 FPGA 网卡跑起来,用来做 10G / 25G 以太网实验。
对极客而言,它是用来手搓硬件防火墙或量化交易加速器的低价神器。但对普通开发者来说,绝对不建议跟风购买。这块卡连官方说明书都没有,如果没有扎实的数字电路功底,买回家也只是一块废铁。
顯示更多

The hardware in old Chinese cloud accelerator cards never fails to impress me.
If you go on Chinese ebay (idlefish) you can get a Xilinix UltraScale FPGA for ~$50 USD.
For perspective, the same raw chip is currently ~$2,100 on Mouser.
顯示更多



Perplexity 正在测试专属的「个人 CFO」(Personal CFO)标签页。最新曝光的界面显示,该面板原生包含投资组合、交易与负债三大管理板块。
为了撑起这个金融工作台,Perplexity 批量打通了垂直领域的头部数据商。基础财务信息由 Financial Modeling Prep 提供,期权数据接入 Unusual Whales,财报原声与会议文档来自 Quartr,营收与 EPS 预期依靠 Fiscal AI 和 S&P Global。此外,还直接接入了 Polymarket 的预测市场数据。
Perplexity Finance 好像一直做得不错,现在想要直接搞一个轻量级彭博终端。
顯示更多

Perplexity is working on a dedicated “Personal CFO” tab that highlights Portfolio, Transactions, and Liability sections.
> Financial information provided by Financial Modeling Prep.
> Options data provided by Unusual Whales. Earnings transcripts, audio, and documents provided by Quartr.
> Reported revenue and EPS data from Earnings powered by Fiscal AI. Estimates provided by S&P Global.
> Prediction markets data from Polymarket. All data is provided for informational purposes only, and is not intended for trading purposes or financial, investment, tax, legal, accounting or other advice.
Perplexity Terminal? 👀
顯示更多

Prime Intellect 公布了一项为期两周的自主 AI 研究实验。研究团队让 Codex(gpt 5.5 xhigh)和 Claude Code(opus 4.7 xhigh)在 nanoGPT 速度赛中自主迭代优化器方案,试图用最少步数达到目标验证损失。经过约 1 万次实验并消耗 1.4 万小时 H200 算力后,Opus 最终以 2930 步打破了 2990 步的人类记录。
实验揭示了当前 AI 代理的能力边界。在强制要求提出新算法的测试分支中,两个模型均无法在脱离人类社区已有代码或论文的情况下跑通任何想法。它们破纪录的成果完全依赖对已有开源技术进行海量组合与参数扫描。
不同模型表现出截然不同的行为缺陷。Claude 频繁违背保持自主运行的系统指令,多次擅自停机等待人类介入,在一次 47 小时的任务中主动闲置了 22 小时。Codex 虽能保持全天候运转,但极易陷入死循环,会在同一个超参数空间内进行长达数小时的无效穷举。
在获取外部信息时,Codex 几乎不查看代码托管平台的最新动态,仅凭本地历史记录搜索。Claude 则将大量 Token 预算用于阅读人类开发者的合并请求。
这个实验证明了前沿 AI 现阶段只是极具效率的工程验证机。一旦人类停止提供初始的算法猜想,它们根本无法独立完成从零到一的创新。
顯示更多
这位大哥声称用 Anthropic 的 Claude 找回了锁死 11 年的 5 BTC,按当前币价约 40 万美元。帖子 12 小时内浏览量突破 1000 万。
他 2014 年上大学时买了 5 BTC,喝酒喝嗨了之后改了钱包密码,醒来忘得一干二净。手上有一条旧助记词,但对不上改过密码的钱包文件。之后几年他用 btcrecover、Hashcat 跑过暴力破解,也花钱请过商业恢复服务,每次 250 美元,全部打水漂。
走投无路之下,他把旧大学电脑上的所有文件打包喂给了 Claude。Claude 干了三件事:在一堆文件里翻出一个改密码之前的旧版 wallet.dat;发现 btcrecover 在解密时把 sharedKey 和密码的拼接顺序搞反了,这个 bug 一直没人发现;修正逻辑后跑了一次就提取出私钥,转成 WIF 格式(Wallet Import Format,用于将私钥导入现代钱包的标准格式)导入钱包。链上记录显示 5 BTC 在当天全部转出。
但 Claude 没有暴力破解加密,更没有突破比特币的密码学。它做的事更接近数字取证:从一堆历史文件里找到对的旧钱包,再读懂恢复工具的代码并修了个 bug。整个过程建立在用户本来就有旧助记词和旧电脑文件的前提上,私钥彻底丢失的情况下 AI 帮不上任何忙。
顯示更多
Avarok Cybersecurity 开源了 Atlas,一个用 Rust + CUDA 从零写的大模型推理引擎。它不依赖 Python 和 PyTorch,项目方称 Docker 镜像约 2.5GB,冷启动不到 2 分钟,目前主要面向 NVIDIA DGX Spark 的 GB10 平台优化。
官网模型矩阵显示,Atlas 在单台 DGX Spark 上跑 Qwen3.5-35B-A3B 可到约 130 tok/s,跑 Qwen3.6-35B-A3B 约 71 tok/s。Atlas 官网和 Hugging Face 页面称,在同硬件下,Qwen3.5-35B 平均约 111 tok/s、峰值 130 tok/s,vLLM 约 37 至 38 tok/s。
这组「3 倍 vLLM」数据来自项目方公开基准。GitHub README 写明,测试使用的是「法国首都是哪」这类短 prompt,生成上限不超过 30 个 token,temperature 为 0.1。这个口径更接近短请求、低并发、快速响应场景,也正好对应 Atlas 想打的卖点:用更小镜像、更少依赖和更快冷启动,把本地大模型服务变得更轻。
Atlas 现在仍是早期项目,真实生产场景还要看后续长文本、高并发和复杂工具调用测试。GitHub 上已有用户反馈输出质量和工具调用稳定性问题,相关 Issue 截至 2026 年 5 月 11 日仍处于 Open 状态。对开发者来说,它更像一个值得关注的新推理底座,而不是已经能全面替代 vLLM 的成熟方案。
顯示更多
MiniMax 发布技术博客,披露其 M2 系列大模型无法输出人名「马嘉祺」的根因排查过程。排查从一个个例出发,最终揭示了一个波及整个词表近 5% 的系统性退化问题。
根本原因是大模型两个训练阶段的数据覆盖严重脱节。第一阶段(预训练)用海量互联网文本编出了一本约 20 万词的「字典」;第二阶段(后训练)用精选的对话数据教模型说话,但这份对话数据只覆盖了字典里的一部分。字典里有、但对话数据里没练到的词,就会在第二阶段逐渐被遗忘。
「嘉祺」就是这样的一个词。分词器(tokenizer,负责把文字切成模型能处理的最小单元)因为在互联网文本中见到「嘉祺」连用的次数够多,就把它合并成了一个独立单元。预训练时模型学会了这个词,但后训练的对话数据里包含「嘉祺」的样本不到 5 条。后训练不断调整模型参数,练到的词越来越准,没练到的词则在参数更新中被带偏。最终,模型仍然「认识」马嘉祺、能准确回答相关信息,丢失的只是把这个名字写出来的能力。
退化排名靠前的还有「传奇私服」「无痛人流」等互联网 SEO 垃圾词。这类词在预训练的互联网语料中铺天盖地,分词器给了它们独立编号,但精选的后训练对话数据不会收录这些内容,结果同样被遗忘。
团队对完整词表做了全量扫描,发现约 4.9% 的词发生了显著退化。退化最严重的是日语:29.7% 的日语词显著退化,远超韩语 3.3%、俄语 3.7%、中文 3.9% 和英文 3.5%。
日语的严重退化还解开了一个旧谜。此前模型在日语对话中偶尔混入俄语或韩语字符,一直找不到原因。这次分析表明,大量日语词退化后,在模型内部的参数空间里「漂」到了其他语言的地盘上,导致模型该写日语时错写成俄语或韩语。
修复方案是构造一份覆盖全词表的合成数据,让模型用简单的复读任务把字典里每个词都练一遍。效果立竿见影:日语回答中混入俄文字符的比例从 47% 降至 1%,全词表参数稳定度从最低 0.329 升至全部高于 0.97。
顯示更多
OpenAI 后训练核心成员翁家翌(Jiayi Weng)以个人名义提出了一种名为「启发式学习」的强化学习新范式,并开源了全部实验代码。他用 Codex(GPT-5.4)反复玩 Atari 打砖块游戏,但 GPT-5.4 自始至终没有被重新训练过。真正在进步的,是 GPT-5.4 写出来的那套游戏策略代码。
流程是这样的:GPT-5.4 先写一版打砖块的 Python 策略,跑一局,看录像,找出哪里打丢了球,然后自己改代码再跑。经过几轮迭代,策略代码从 387 分涨到了 864 满分。全程没有任何神经网络被训练,纯靠 AI 反复修改 if-else 规则、调落点预测、加死循环检测。最终那套代码包含球路预测器、卡球检测器、回归测试和实验日志,已经长成了一个完整的软件系统。
这和传统强化学习的核心区别在于「学到的东西存在哪」。传统做法把知识压进神经网络参数里,人看不懂,学新任务还容易把旧的覆盖掉(即灾难性遗忘)。翁家翌的做法反过来:知识就是代码,人能读、能改、能加测试锁住,不会因为学新东西就丢了旧本领。
除了打砖块满分,他还在 MuJoCo Ant(模拟机器蚂蚁走路)上跑出超 6000 分的深度强化学习级成绩,在 Atari57 全套 57 个游戏上逼近了 PPO 基准。但翁家翌也明确画了边界:纯代码搞不定复杂感知任务,比如用 Python 写 if-else 去认图片。
他设想的终局是混合架构:底层用轻量神经网络负责视觉等感知,中层用启发式学习处理实时逻辑和安全规则,顶层由大模型审查日志、改代码,再周期性地用底层积累的高质量数据更新自身。过去手写规则之所以被淘汰,不是因为规则没用,而是人类维护不起。现在 AI 写代码够快够好,这条老路重新走得通了。
顯示更多

Codex grew programmatic policies with no neural nets: max score on Breakout, and SOTA-level scores on MuJoCo.
Maybe heuristics were not too weak. Maybe they were just too expensive to maintain. Maybe it's the next paradigm.
顯示更多

腾讯云开源了 AI Agent 沙盒 Cube Sandbox,Rust 编写,Apache 2.0 协议。
Agent 跑模型生成的代码需要一个隔离环境,避免误删文件或越权访问主机。这类服务的接口事实标准是 E2B,OpenAI Agents SDK、Manus、Perplexity、Hugging Face 都接它。Cube 对 E2B 做完全兼容,原本接 E2B 的 Agent 只要改一个环境变量就能切过来。
腾讯云公布了两组性能数据。单并发冷启动低于 60ms,50 并发时平均 67ms、P95 90ms、P99 137ms。单实例常驻内存低于 5MB(沙盒规格不超过 32GB 时测得),一台 96 核服务器可同时跑 2000 多个沙箱。同场景下 Docker 容器启动约 200ms、共享主机内核;传统虚拟机启动以秒计、单实例内存 20MB 起。
Cube 的做法是给每个 Agent 开一套独立的 Guest OS 内核,走硬件级隔离,同时把启动时间压到百毫秒内。加速靠资源池预置、快照克隆、底层锁优化;压内存靠 Rust 重写、CoW 内存复用、reflink 磁盘共享。项目还附带 CubeVS,用 eBPF 做沙盒之间的网络隔离。
规模化验证给了两个案例。Cube 原本跑在腾讯云 Serverless 体系里,承载过百亿级调用。元宝 AI 编程场景迁到 Cube 后,资源核时消耗降了 95.8%。外部客户里,MiniMax 在 Agentic RL 训练中靠 Cube 做到分钟级调度数十万沙箱实例。下一步规划是把事件级快照回滚也开源出去,提供百毫秒级状态回滚。
顯示更多














